

이전 포스팅에서 역할에 맞는 클래스를 설계했습니다.
[사이드 프로젝트] 크롤링 마이그레이션, Pandas CSV 용량 줄이기 - Parquet 으로 1/10 용량으로 압축하
최근에 사이드프로젝트 백엔드를 작업하다, 데이터 작업도 같이 맡게 되었습니다. 기존엔 프론트엔드 개발자인 형 혼자서 담당했는데, 개발 리소스를 분산하고자 배우고 있네요. ☺️ 데이터를
itchipmunk.tistory.com
그 중 아래 클래스를 만들었는데요~
- ✅ Loader : 일감 가져오기
- ✅ Scheduler : 일감 분배하기
- ✅ Scrapper : 분배된 일감으로 수집하기
- ❌ Storage : 데이터 저장하기
- ❌ Uploader: 외부 스토리지로 업로드하기
어젯밤 만들지 못한 Storage, Uploader 클래스를 만들어봤습니다.
뿐만 아니라 비동기 작업을 위해 Asyncio 를 사용 중인데요!
동기 작업만 지원할 때 어떻게 처리했는지 정리하고자 합니다.
1. Storage / Uploader 클래스 추가
1.1. 특정 파일 형식을 처리하는 Storage 클래스
Storage 클래스는 형식에 맞게 데이터를 저장하거나, 불러오는 역할입니다.
CsvStorage, ParquetStorage 으로 특정 형식으로 구분했습니다.
# Abstract class
from abc import ABCMeta, abstractmethod
# Pandas
from pandas import DataFrame
class Storage(metaclass=ABCMeta):
@abstractmethod
async def save(self, file_name: str, df: DataFrame):
raise NotImplementedError
@abstractmethod
async def load(self, file_name: str) -> DataFrame:
raise NotImplementedError
# Builtins
import os
# Typing
from typing import Awaitable
# Common Setup
from common.logger import *
# Abstract Class
from .storage import *
# Pandas
import pandas as pd
from pandas import DataFrame
# Asynchronous
import asyncio
from concurrent.futures import Executor
class CsvStorage(Storage):
logger = get_logger("CsvStorage")
def __init__(self, executor: Executor):
self.executor = executor
async def save(self, file_name: str, df: DataFrame):
loop = asyncio.get_event_loop()
mode = 'w'
header = True
# 첫 생성 이후 모두 새로운 행으로 추가합니다.
if os.path.exists(file_name):
mode = 'a'
header = False
await loop.run_in_executor(
self.executor,
self.to_csv,
df,
file_name,
mode,
header,
)
def to_csv(self, df: DataFrame, file_name: str, mode: str, header: bool):
df.to_csv(file_name, index=False, mode=mode, encoding='utf-8-sig', header=header)
self.logger.info(f"총 {len(df)} 개의 XXX를 {file_name} 파일로 저장했습니다.")
async def load(self, file_name: str, dtype: dict = None) -> DataFrame:
loop = asyncio.get_event_loop()
return await loop.run_in_executor(
self.executor,
self.read_csv,
file_name,
dtype,
)
def read_csv(self, file_name: str, dtype: dict = None):
return pd.read_csv(file_name, keep_default_na=False, dtype=dtype)
# Common Setup
from common.logger import *
# Abstract Class
from storage import *
# Pandas
from pandas import DataFrame
# Asynchronous
import asyncio
from concurrent.futures import Executor
class ParquetStorage(Storage):
logger = get_logger("ParquetStorage")
def __init__(self, executor: Executor):
self.executor = executor
async def save(self, file_name: str, df: DataFrame):
loop = asyncio.get_event_loop()
await loop.run_in_executor(
self.executor,
self.to_parquet,
df,
file_name,
)
def to_parquet(self, df: DataFrame, file_name: str):
df.to_parquet(
file_name,
compression='brotli',
engine='pyarrow',
index=False
)
self.logger.info(f"{file_name} parquet 파일로 저장했습니다.")
async def load(self, file_name: str, dtype: dict = None) -> DataFrame:
raise NotImplementedError
CsvStorage 와 ParquetStorage 는 각각 csv 파일, parquet 파일을 다룹니다.
두 파일마다 저장하거나 불러오는 요구사항이 다른걸 확인할 수 있습니다.
두 클래스의 차이점은 다음과 같습니다.
CsvStorage 는 저장 시 새로 생성하고 이후엔 내용을 추가하는 식으로 저장합니다.
ParquetStorage 는 불러오는 메소드가 필요치 않습니다.
1.2. 외부 스토리지로 업로드하는 Uploader 클래스
Uploader 클래스는 외부 스토리지로 업로드하는 책임을 갖습니다.
현재 벤더가 AWS S3 뿐이라, S3Uploader 클래스만 존재합니다.
# Abstract class
from abc import ABCMeta, abstractmethod
class Uploader(metaclass=ABCMeta):
@abstractmethod
async def upload(self, file_name: str, key: str):
raise NotImplementedError
# Common Setup
from common.logger import *
from common.s3 import *
# Abstract Class
from .uploader import *
# Asynchronous
import asyncio
import aiofiles
from concurrent.futures import Executor
class S3Uploader(Uploader):
logger = get_logger("S3Uploader")
def __init__(self, executor: Executor, bucket_name: str):
self.executor = executor
self.bucket_name = bucket_name
async def upload(self, file_name: str, key: str):
await self.upload_fileobj(file_name, key)
async def upload_fileobj(self, file_name: str, key: str):
async with aiofiles.open(file_name, 'rb') as f:
contents = await f.read()
loop = asyncio.get_running_loop()
await loop.run_in_executor(
self.executor,
self.put_object,
contents,
key
)
def put_object(self, contents: bytes, key: str):
s3.put_object(Body=contents, Bucket=self.bucket_name, Key=key)
self.logger.info(f"{key} 파일을 S3 {self.bucket_name} 버킷에 업로드했습니다.")
S3Uploader 에선 기존 파일을 불러와 S3 로 업로드하는 역할을 맡습니다.
'버킷'은 S3 벤더에만 있는 개념이라 생성자로 입력받습니다.
1.3. 메인 코드 변경
# Submodules
from loader import PostgresLoader
from scheduler import EvenScheduler
from scrapper import NCFScrapper
from storage import CsvStorage, ParquetStorage
from uploader import S3Uploader
BUCKET_NAME = 'xxxxx'
thread_executor = ThreadPoolExecutor(10)
async def main():
...
storage = CsvStorage(thread_executor)
csv_file_name = 'xxx.csv'
while True:
...
df_result = pd.DataFrame(result_flatten)
await storage.save(csv_file_name, df_result)
...
all_df = await storage.load(csv_file_name, dtype=XXX_DTYPE)
...
parquet_file_name = "xxx.parquet"
storage = ParquetStorage(thread_executor)
await storage.save(parquet_file_name, all_df)
uploader = S3Uploader(thread_executor, BUCKET_NAME)
key = "%s.parquet" % datetime.today().strftime("%Y%m%d")
await uploader.upload(parquet_file_name, key)
...
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
기존 코드와 비교해서 구현 코드가 직접 붙어있었던 것과 다르게,
역할이 부여된 클래스로 분리해서 가독성을 높였습니다.
코드 단락별로 어떤 역할을 하는 코드인지 파악하기가 쉬워졌습니다.
main 메소드 또한 기능별로 메소드를 분리할 순 있지만, 이번 작업엔 포함시키지 않았습니다.
2. Asyncio 적용기
asyncio 는 async/await 구문을 사용해 동시성 코드를 작성하는 라이브러리입니다.
고성능 네트워크 및 웹 서버, 데이터베이스 연결 라이브러리, 분산 작업 큐 등을 사용하는 여러 파이썬 비동기 프레임워크에서도 채택하고 있습니다.
asyncio 는 I/O 병목과 더불어 구조화된 네트워크 코드를 작성하는 데 적합합니다.
I/O 바운드 작업과 CPU 바운드 작업을 설명합니다.
우리 CPU 는 메모리에서 명령어를 가져와 차례대로 연산해주는 친구입니다.
CPU 바운드 작업이란, 계속해서 명령어를 가져와 처리해주는 작업을 의미해요.
반대로, I/O 바운드 작업은 CPU 의 연산과 무관합니다.
주변 장치(파일, 네트워크 등)의 작업 속도는 CPU의 연산 속도보다 헌저히 느리기에,
데이터가 CPU에 들어올 때 까지 CPU 는 일을 하지 않고 기다립니다!
CPU가 일을 하지 않는 시간이 너무 아깝다고 생각이 들지 않나요~?
I/O 바운드 작업이 일어나는 동안, CPU 를 다른 일로 하게 보내버리는 게 효율이 좋겠죠?
비동기 작업이 바로, I/O 작업을 기다리기까지 CPU 를 일하게 만드는 비법입니다.
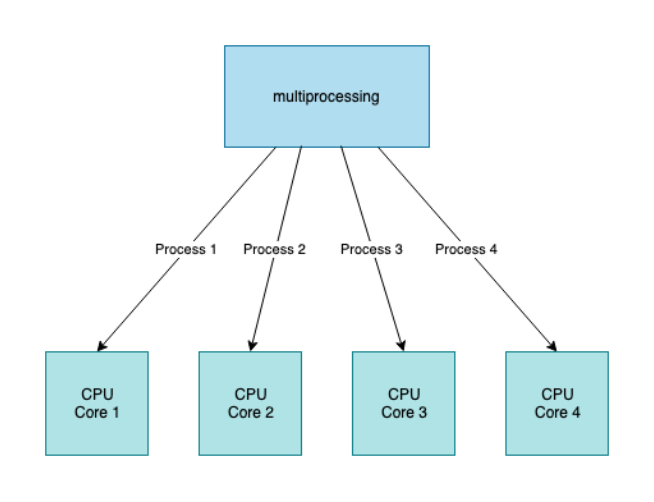
반대로, CPU 바운드 작업은 비동기 작업보단, CPU 코어를 활용하는 방법을 이용하면 됩니다.
멀티프로세스를 활용한다든지, 멀티스레드를 활용하는 방법이 있습니다.
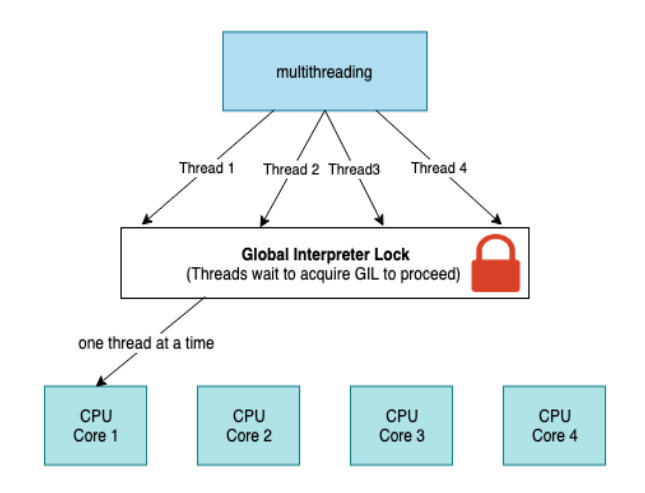
다만, 파이썬의 경우 한 프로그램에서 한 스레드만 인터프리터를 점유할 수 있는 GIL(Global Interpreter Lock)이 있기 때문에,
멀티코어의 이점을 활용하려면, 멀티프로세스를 사용하는 쪽입니다.
GIL 은 한 번에 하나의 스레드만 파이썬 바이트코드를 실행하도록 강제하는데요~
파이썬은 GC(Garbage Collector)로 메모리 관리를 자동으로 해줍니다.
만약 파이썬 바이트코드를 동시에 실행시킨다고 가정해 볼게요.
GC에서 메모리에서 자원을 해제함과 동시에, 다른 스레드가 그 자원에 접근한다면 예상치 못한 오류가 발생할 수 있습니다.
프로그래머가 스레드를 다룰 때, 늘 GC가 동시에 동작한다는 가정과 동기화를 신경써야 해서 복잡성이 올라갔을 걸로 예상돼요.
다만, 여러 스레드가 메모리 자원을 수정해도 데이터 무결성을 보장해주는 장점은 있습니다.
따라서 스레드로 연산 처리 성능을 향상시키기보다는, 프로세스를 더 늘려서 성능을 향상시킵니다.
I/O 바운드에서 CPU 처리 성능을 향상시키려면, I/O 바운드 시간에 노는 CPU 를 일하게 만들어야 합니다.
CPU를 기다리게 하지 말고, I/O를 비동기로 처리하고 프로그램에 알려주는 건 운영체제(커널)에 맡깁니다!
운영체제가 프로그램에 알려주면(비동기), 그 때서야 다음 작업을 이어나가게 되는거죠~
그렇다면 asyncio 는 어떻게 동작할까요?
큐와 이벤트 루프를 활용합니다.

싱글 스레드로 이벤트 루프를 계속 돌면서, 큐에 적재된 작업을 처리합니다.
작업을 처리할 때 Executor 으로 ThreadPool 을 활용할 수도, ProcessPool 을 활용할 수도 있습니다. (기본은 ThreadPoolExecutor)
비동기 작업을 운영체제(커널)마다 최적화된 방법으로 일을 맡깁니다. 그리고 다음 작업을 실행시켜 동시에 실행되는 것처럼 보여줍니다.
일을 마치면 다시 큐에 콜백 큐로 넣어, 이벤트 루프가 추후에 실행하게 하는 식입니다.
전통적으론 Task 하나 하나마다 스레드를 생성하거나, 스레드풀안에 있는 스레드와 매칭을 시켰는데요.
asyncio 는 많은 작업을 스레드(또는 프로세스)와 매칭 시켜주는 건 물론, 작업들을 스케쥴링까지 해주는 장점이 있습니다.
2.1. 실제 코드에 적용해보기
자, 이제 코드에 한 번 적용해보죠.
CPU 바운드 보다는, I/O 바운드 작업이 포함된 코드를 적용해야겠죠!?
I/O 바운드 작업 중 네트워크 작업, 파일 작업이 주로 이루니 유심히 살펴봅시다.
DB 작업을 예를 들어보죠.
async def load(self) -> pd.DataFrame:
...
xxx = pd.read_sql_query(query, engine)
return xxx
pandas 에서 read_sql_query 메소드로 SQL 쿼리를 실행시켜 불러오고 있습니다.
근데 잠깐만, pandas 에서 비동기 작업을 지원하나요??
아쉽게도 pandas 에서 비동기 async/await 구조로 작성되지 않았다고 하는데요.
그럼 어떻게 asyncio 에 큐로 보낼 수 있을까요?
2.2. 라이브러리가 비동기를 지원하지 않는다면?
바로 asyncio 의 이벤트루프에 하나의 작업을 새로 만들어버리면 됩니다.
# postgres_loader.py
class PostgresLoader(AbstractLoader):
logger = get_logger("PostgresLoader")
def __init__(self, executor: Executor):
self.executor = executor
async def load(self) -> pd.DataFrame:
...
loop = asyncio.get_event_loop()
xxx = await loop.run_in_executor(
self.executor,
pd.read_sql_query,
query,
engine
)
return xxx# main.py
thread_executor = ThreadPoolExecutor(10)
async def main():
...
loader = PostgresLoader(thread_executor)
data = await loader.load()
...
전역적으로 사용할 ThreadPoolExecutor 을 만들고, 생성자로 주입했습니다.
asyncio 이벤트루프에 해당 스레드풀로 작업 실행이 되게끔 큐에 쌓아줍니다.
이렇게 기존 동기 코드를 이벤트 루프의 작업에 넣을 수 있게 됐습니다.
2.3. 비동기를 지원하는 라이브러리
네트워크와 파일 비동기 처리를 위해 aiohttp 와 aiofiles 를 제공합니다.
현재 프로젝트에선 이미 aiohttp 으로 비동기로 네트워크를 처리하고 있어요.
# Asynchronous
from aiohttp import ClientSession, ClientTimeout
# Log
from common.logger import *
logger = get_logger("Web Client")
class WebClient:
DEFAULT_HEADERS = {
"Content-Type": "application/json; charset=utf-8"
}
DEFAULT_TIMEOUT = 60
async def get(self, url: str) -> dict:
async with ClientSession(headers=self.DEFAULT_HEADERS,
timeout=ClientTimeout(total=self.DEFAULT_TIMEOUT)) as session:
async with session.get(url) as response:
logger.debug("session started - [GET] %s" % url)
json = await response.json()
logger.debug(json)
return json
async def post(self, url: str, data: dict) -> dict:
async with ClientSession(headers=self.DEFAULT_HEADERS,
timeout=ClientTimeout(total=self.DEFAULT_TIMEOUT)) as session:
async with session.post(url, json=data) as response:
logger.debug("session started - [POST] %s" % url)
logger.debug(data)
json = await response.json()
logger.debug(json)
return json
이번에 새로 aiofiles 을 적용해서 업로드할 때 비동기로 파일읽기 처리하고 있습니다.
# Common Setup
from common.logger import *
from common.s3 import *
# Abstract Class
from .uploader import *
# Asynchronous
import asyncio
import aiofiles
from concurrent.futures import Executor
class S3Uploader(Uploader):
logger = get_logger("S3Uploader")
def __init__(self, executor: Executor, bucket_name: str):
self.executor = executor
self.bucket_name = bucket_name
async def upload(self, file_name: str, key: str):
await self.upload_fileobj(file_name, key)
async def upload_fileobj(self, file_name: str, key: str):
async with aiofiles.open(file_name, 'rb') as f:
contents = await f.read()
loop = asyncio.get_running_loop()
await loop.run_in_executor(
self.executor,
self.put_object,
contents,
key
)
def put_object(self, contents: bytes, key: str):
s3.put_object(Body=contents, Bucket=self.bucket_name, Key=key)
self.logger.info(f"{key} 파일을 S3 {self.bucket_name} 버킷에 업로드했습니다.")
upload_fileobj 메소드에서 aiofiles 으로 비동기로 파일을 읽는 걸 확인할 수 있어요.
뿐만 아니라, 비동기를 지원하지 않는 boto3 s3 client 를 이벤트 루프 작업으로 보내주는 작업도 확인할 수 있습니다.
run_in_executor 할 때 매개변수 키워드로 값을 할당하지 못하다보니, 따로 메소드를 분리해야하는 번거로움도 있었네요.
마무리
기존 크롤링 코드를 객체지향적으로 확장성 있고 역할별로 잘 분리된 것 같아서 뿌듯합니다.
또한 asyncio 를 사용하면서, 왜 I/O 바운드에서 효용이 좋은지 이해할 수 있는 계기가 되었습니다.
GIL 도 오랜만에 다시 보게 됐네요. 😁
조금 더 비동기처리를 위한다면, aiopath 를 이용해서 파일을 조회하는 방법도 있고, aiobotocore 를 이용해서 s3 업로드/다운로드를 비동기 처리하는 방법도 있습니다!
aiopath 까지 할 필요성은 못 느꼈습니다..!
aiobotocore 도 공식 라이브러리가 아니고, 다른 코드에서 기존 boto3 라이브러리가 쓰였는데요.
나중에 팀과 상의 후에 적용해보는 식으로 하면 좋을 것 같아요. :)
다른 게시글로 찾아뵙겠습니다.
'프로젝트 > 장기 프로젝트' 카테고리의 다른 글
| MOTI #5. 인증서 만료로 인한 API 서버 접속 장애 해결 (0) | 2024.07.23 |
|---|---|
| MOTI #4. 장고 어드민 버전 업데이트하기 (Poetry 전환) / ChatGPT 에서 질문 추천받아 추가하기 (0) | 2024.06.23 |
| 부스패치 #1. 크롤링 마이그레이션, Pandas CSV 용량 줄이기 - Parquet 으로 1/10 용량으로 압축하기 (0) | 2024.03.03 |
| Swagger OpenAPI 3.0 에서 allOf 으로 확장해서 공통 응답 적용하기 (0) | 2024.02.04 |
| [뮤즐리 이슈 해결] LetsEncrypt(Certbot) 도메인 인증서 만료 / 갱신 / 크론탭 등록 (0) | 2023.11.24 |
댓글