[혼공학습단 9기] #8. 컬렉션 프레임워크, 자료구조 날로 먹기

안녕하세요, 다람쥐 입니다. 🐿
벌써 혼공학습단 9기 혼공자바 5주차 진도네요!
혼자 공부하는 자바가 책 이름대로 혼자 공부하기 편하더라고요!
빠르게 자바를 한 번 훑기에는 이보다 좋은 책이 없는 것 같네요.
혼공학습단 9기 혼공자바 5주차는 Chapter 13 진도인데요.
Chapter 13 진도는 컬렉션 프레임워크 입니다.
개발을 공부하다보면 자연스레 문법을 배우면 자료구조, 알고리즘을 배우게 되는데요.
자바에선 컬렉션 프레임워크에 해당되는데요.
직접 구현하는 게 아니라 기본 라이브러리로 제공하고 있어요.
그래서 사용법만 알면 돼서 공부하기가 한층 편한 것 같아요.
자바에서 기본 라이브러리로 채택될 만큼 표준화가 되어 있고 신뢰할 만 합니다.
모든 자바 개발자 분들이 사용할 수 있는 자료구조 API 를 제공하기에
저희 같은 초보 개발자는 날로, 편하게 원리만 이해하고 잘 사용하기만 하면은 학습 시간을 단축할 수 있습니다. ☺️
컬렉션 프레임워크
자바는 널리 알려져 있는 자료구조를 사용해 객체를 효율적으로 추가, 삭제, 검색 할 수 있도록 인터페이스와 구현 클래스를 제공합니다.
자바 컬렉션 프레임워크는 java.util 패키지에서 제공합니다.
컬렉션은 객체의 저장을 의미하고, 프레임워크는 사용 방법을 정해놓은 라이브러리를 뜻합니다.
사용 방법을 정의한 인터페이스와 객체를 저장하는 다양한 컬렉션 클래스 (구현 클래스) 를 제공합니다.
컬렉션 프레임워크의 주요 인터페이스로는 List, Set, Map 이 있습니다.
Java SE 11 & JDK 11 기준으로 각 인터페이스를 구현한 구현 클래스 종류는 다음과 같습니다.
List, Queue, Set, Map 을 기준으로 하위 인터페이스, 구현 클래스들이 있습니다.
Vector, Stack, ArrayList, LinkedList, Deque, ArrayDeque, PriorityQueue, HashSet, LinkedHashSet, SortedSet, NaviableSet, TreeSet, SortedMap, NavigableMap, TreeMap, HashMap, LinkedHashMap, IdentityHashMap, WeakHashMap, HashTable, Properties 등이 있습니다.

혼자 공부하는 자바에선 아래 종류만 설명하는데요~
- List
- ArrayList
- Vector
- LinkedList
- Set
- HashSet
- TreeSet
- Map
- HashMap
- Hashtable
- TreeMap
- Properties
각 컬렉션마다 어떤 특징이 있는지 사용법은 어떻게 되는지 예제와 함께 설명합니다.
우선 이들 먼저 알아보고 다른 구현 클래스, 인터페이스는 왜 나왔고 어떻게 구현되었고, 어떻게 쓰는지 자세히 알아보도록 하죠!
List 컬렉션
List 컬렉션은 배열과 비슷하게 객체를 인덱스로 관리합니다.
그러면 배열과의 차이점이 무엇인지 중요한데요~
바로 '저장 용량' (capacity) 이 자동으로 증가하며 객체를 저장할 때 인덱스가 자동으로 부여됩니다.
그리고 추가, 삭제, 검색을 위한 다양한 메소드가 제공됩니다.
List 컬렉션은 객체 자체를 저장하는 것이 아니라 객체의 번지를 참고합니다.
그렇기에 동일한 객체를 중복 저장할 수 있는데요.
이 경우 동일한 번지가 참조됩니다.
null 도 저장이 가능합니다.
null 을 가리키는 인덱스는 따로 객체를 참조하지 않습니다.
List 컬렉션은 인터페이스로 되어 있습니다.
List (Java SE 11 & JDK 11 )
An ordered collection (also known as a sequence). The user of this interface has precise control over where in the list each element is inserted. The user can access elements by their integer index (position in the list), and search for elements in the lis
docs.oracle.com
다음은 List 컬렉션에서 공통적으로 사용 가능한 List 인터페이스의 메소드입니다.
인덱스로 객체를 관리하기에 인덱스를 매개 변수로 갖는 메소드가 많습니다.
- 객체 추가
- boolean add(E e)
- 주어진 객체를 맨 끝에 추가합니다.
- void add(int index, E element)
- 주어진 인덱스에 객체를 추가합니다.
- E set(int index, E element)
- 주어진 인덱스에 저장된 객체를 주어진 객체로 바꿉니다.
- boolean add(E e)
- 객체 검색
- boolean contains(Object o)
- 주어진 객체가 저장되어 있는지 조사합니다.
- E get(int index)
- 주어진 인덱스에 저장된 객체를 리턴합니다.
- boolean isEmpty()
- 컬렉션이 비어 있는지 조사합니다.
- int size()
- 저장되어 있는 전체 객체 수를 리턴합니다.
- boolean contains(Object o)
- 객체 삭제
- void clear()
- 저장된 모든 객체를 삭제합니다.
- E remove(int index)
- 주어진 인덱스에 저장된 객체를 삭제합니다.
- boolean remove(Object o)
- 주어진 객체를 삭제합니다.
- void clear()
여기서 E 는 제네릭을 의미합니다.
List 컬렉션에 저장된 모든 객체를 하나씩 가져와 순회하고자 한다면 인덱스를 이용하는 방법과 향상된 for 문을 이용하는 방법이 있습니다.
List<String> list = ...;
// 1. 인덱스 순회 for 문
for (int i = 0; i < list.size(); i++) {
String str = list.get(i);
}
// 2. 향상된 for 문
for (String str : list) {
...
}향상된 for 문은 List 컬렉션에 저장된 객체 수만큼 반복하면서 객체를 하나씩 str 변수에 대입합니다.
ArrayList
ArrayList 를 생성하는 방법은 다음과 같습니다.
제네릭 E 타입 파라미터를 List<E> 에 표기하면 ArrayList 에도 똑같이 표기하거나 두 번째 줄 처럼 생략해도 됩니다.
List<String> list = new ArrayList<String>();
List<String> list = new ArrayList<>();<> 연산자는 다이아몬드 연산자라고 부르며 JDK 7 이후에 컴파일러가 타입을 추론해줍니다.
타입 추론이란 컴파일러가 타입을 유추할 수 있으면 그 타입으로 자동으로 넣어줍니다.
JDK 7 이전에는 첫 번째 방법으로 선언 시에 타입을 명시해줘야 합니다.
기본 생성자로 ArrayList 객체를 생성하면 내부에 10개의 객체를 저장할 수 있는 초기 용량(capacity) 을 가집니다.
저장되는 객체 수가 늘어나면 용량이 자동으로 증가합니다.
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
...
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
ArrayList 에 객체를 추가하면 0번 인덱스부터 차례대로 저장됩니다.
ArrayList 에서 특정 인덱스의 객체를 제거하면 바로 뒤 인덱스부터 마지막 인덱스까지 모두 앞으로 1 씩 당겨집니다.
마찬가지로 특정 인덱스에 객체를 삽입하면 해당 인덱스부터 마지막 인덱스까지 모두 1 씩 밀려납니다.
저장된 객체 수가 많고, 특정 인덱스에 객체를 추가하거나 제거하는 일이 빈번하다면 ArrayList 보다는 LinkedList 를 사용하는 것이 효율적입니다. 인덱스를 이용해 객체를 찾거나 맨 마지막에 객체를 추가하는 경우에는 ArrayList 가 더 좋은 성능을 발휘합니다.
import java.util.ArrayList;
import java.util.List;
public class Example {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("Java");
list.add("JDBC");
list.add("Servlet/JSP");
list.add(2, "Database");
list.add("iBATIS");
int size = list.size();
System.out.println("총 객체수: " + size);
System.out.println();
String skill = list.get(2);
System.out.println("2: " + skill);
System.out.println();
for (int i = 0; i < list.size(); i++) {
String str = list.get(i);
System.out.println(i + ":" + str);
}
System.out.println();
list.remove(2); // 'Database' removed
list.remove(2); // 'Servlet/JSP' removed
list.remove("iBATIS");
for (int i = 0; i < list.size(); i++) {
String str = list.get(i);
System.out.println(i + ":" + str);
}
}
}
총 객체수: 5
2: Database
0:Java
1:JDBC
2:Database
3:Servlet/JSP
4:iBATIS
0:Java
1:JDBC
Vector
Vector 는 ArrayList 와 동일한 내부 구조를 가집니다.
ArrayList 와 마찬가지로 저장할 객체 타입을 제네릭으로 표기합니다.
List<String> list = new Vector<String>();
List<String> list = new Vector<>();
ArrayList 와 다른 점은 다음과 같습니다.
- 동기화(synchronized)된 메소드로 구성되어 있어 스레드에 안전합니다.
- 멀티 스레드가 동시에 Vector 의 메소드를 실행할 수 없습니다.
- 하나의 스레드가 메소드 실행을 완료해야만 다른 스레드가 메소드를 실행할 수 있습니다.
public synchronized boolean add(E e) {
modCount++;
add(e, elementData, elementCount);
return true;
}
...
public synchronized boolean removeElement(Object obj) {
modCount++;
int i = indexOf(obj);
if (i >= 0) {
removeElementAt(i);
return true;
}
return false;
}
아래 코드는 한 Vector에 스레드A, 스레드B 으로 각각 1,000 개 씩 추가합니다.
과연 2000 개가 될까요?
// Board.java
public class Board {
String subject;
String content;
String writer;
public Board(String subject, String content, String writer) {
this.subject = subject;
this.content = content;
this.writer = writer;
}
}
// Example.java
import java.util.*;
public class Example {
public static void main(String[] args) {
List<Board> list = new Vector<>();
Thread threadA = new Thread() {
@Override
public void run() {
for (int i = 1; i <= 1000; i++) {
list.add(new Board("제목"+i, "내용"+i, "글쓴이"+i));
}
}
};
Thread threadB = new Thread() {
@Override
public void run() {
for (int i = 1001; i <= 2000; i++) {
list.add(new Board("제목"+i, "내용"+i, "글쓴이"+i));
}
}
};
threadA.start();
threadB.start();
try {
threadA.join();
threadB.join();
} catch (Exception e) {}
int size = list.size();
System.out.println("총 객체 수:" + size);
System.out.println();
}
}
총 객체 수:2000총 객체 수 2000 으로 맞춰집니다.
만약 ArrayList 으로 바꾼다면 결과가 어떻게 될까요?
...
List<Board> list = new ArrayList<>();
...
총 객체 수:1841총 객체 수가 2000이 아니게 됩니다.
실행할 때 마다 달라지게 되는데요.
thread-safe 하지 않은 객체는 따로 동기화 메소드로 사용자가 관리해줘야 합니다.
public class Example {
public static synchronized void add(List<Board> list, int i) {
list.add(new Board("제목"+i, "내용"+i, "글쓴이"+i));
}
public static void main(String[] args) {
List<Board> list = new ArrayList<>();
Thread threadA = new Thread() {
@Override
public void run() {
for (int i = 1; i <= 1000; i++) {
add(list, i);
}
}
};
Thread threadB = new Thread() {
@Override
public void run() {
for (int i = 1001; i <= 2000; i++) {
add(list, i);
}
}
};
threadA.start();
threadB.start();
try {
threadA.join();
threadB.join();
} catch (Exception e) {}
int size = list.size();
System.out.println("총 객체 수:" + size);
System.out.println();
}
}
LinkedList
ArrayList와 사용 방법은 같으나, 구현 방법이 다릅니다. 인접 참조를 링크해서 체인처럼 관리합니다.
특정 인덱스의 객체를 제거하면 앞 뒤 링크만 사라지고 나머지 링크는 변경되지 않습니다.
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class Example {
public static void main(String[] args) {
List<String> list1 = new ArrayList<>();
List<String> list2 = new LinkedList<>();
long startTime, endTime;
startTime = System.nanoTime();
for (int i = 0; i < 10000; i++) {
list1.add(0, String.valueOf(i));
}
endTime = System.nanoTime();
System.out.println("ArrayList 걸린시간: " + (endTime - startTime) + " ns"); // ArrayList 걸린시간: 12843459 ns
startTime = System.nanoTime();
for (int i = 0; i < 10000; i++) {
list2.add(0, String.valueOf(i));
}
endTime = System.nanoTime();
System.out.println("LinkedList 걸린시간: " + (endTime - startTime) + " ns"); // LinkedList 걸린시간: 3425625 ns
}
}
Set 컬렉션
List 컬렉션은 객체의 저장 순서를 유지하지만 Set 컬렉션은 저장 순서가 유지되지 않습니다.
또한 객체를 중복해서 저장할 수 없고 하나의 null 만 저장할 수 있습니다.
- 객체 추가
- boolean add(E e)
- 주어진 객체를 저장합니다. 객체가 성공적으로 저장되면 true를 리턴하고 중복 객체면 false를 리턴합니다.
- boolean add(E e)
- 객체 검색
- boolean contains(Object o)
- 주어진 객체가 저장되어 있는지 조사합니다.
- boolean isEmpty()
- 컬렉션이 비어 있는지 조사합니다.
- Iterator<E> iterator()
- 저장된 객체를 한 번씩 가져오는 반복자를 리턴합니다.
- int size()
- 저장되어 있는 전체 객체 수를 리턴합니다.
- boolean contains(Object o)
- 객체 삭제
- void clear()
- 저장된 모든 객체를 삭제합니다.
- boolean remove(Object o)
- 주어진 객체를 삭제합니다.
- void clear()
Set 컬렉션은 인덱스로 객체를 검색하지 않고 한 번씩 반복해서 가져오는 반복자가 있습니다.
- boolean hasNext()
- 가져올 객체가 있으면 true를 리턴하고 없으면 false를 리턴합니다.
- E next()
- 컬렉션에서 하나의 객체를 가져옵니다.
- void remove()
- Set 컬렉션에서 객체를 제거합니다.
HashSet
HashSet은 객체들을 순서 없이 저장하고 동일한 객체는 중복 저장하지 않습니다.
HashSet이 판단하는 동일한 객체는 같은 인스턴스 뿐 아니라 hashCode() 메소드를 호출하여 비교합니다.
import java.util.*;
public class Example {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("Java");
set.add("JDBC");
set.add("Servlet/JSP");
set.add("Java");
set.add("iBATIS");
int size = set.size();
System.out.println("총 객체수: " + size);
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()) {
String element = iterator.next();
System.out.println("\t" + element);
}
set.remove("JDBC");
set.remove("iBATIS");
System.out.println("총 객체수: " + set.size());
iterator = set.iterator();
for (String element : set) {
System.out.println("\t" + element);
}
set.clear();
if (set.isEmpty()) {
System.out.println("비어 있음");
}
}
}
총 객체수: 4
Java
JDBC
Servlet/JSP
iBATIS
총 객체수: 2
Java
Servlet/JSP
비어 있음HashSet 은 내부적으로 HashMap 을 사용합니다.
HashMap 의 키를 추가하는데요. 그 값으로는 빈 Object 객체를 추가합니다.
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element {@code e} to this set if
* this set contains no element {@code e2} such that
* {@code Objects.equals(e, e2)}.
* If this set already contains the element, the call leaves the set
* unchanged and returns {@code false}.
*
* @param e element to be added to this set
* @return {@code true} if this set did not already contain the specified
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
Map 컬렉션
Map 컬렉션으 키(key)와 값(value)으로 구성된 Map.Entry 객체를 저장하는 구조를 가지고 있습니다.
Entry는 Map 인터페이스 내부에 선언된 중첩 인터페이스입니다. 여기서 키와 값은 모두 객체입니다.
기존 키와 동일한 키로 저장하면 기존 값은 얻어지고 새로운 값으로 대체됩니다.
- 객체 추가
- V put(K key, V value)
- 주어진 키로 값을 저장합니다. 새로운 키일 경우 null 을 리턴하고 동일한 키가 있을 경우 값을 대체하고 이전 값을 리턴합니다.
- V put(K key, V value)
- 객체 검색
- boolean containsKey(Object key) : 주어진 키가 있는지 확인합니다.
- boolean containsValue(Object value) : 주어진 값이 있는지 여부를 확인합니다.
- Set<Map, Entry<K, V>> entrySet() : 키와 값의 쌍으로 구성된 모든 Map.Entry 객체를 Set에 담아서 리턴합니다.
- V get(Object key) : 주어진 키가 있는 값을 리턴합니다.
- boolean isEmpty() : 컬렉션이 비어 있는지 여부를 확인합니다.
- Set<K> keySet() : 모든 키를 Set 객체에 담아서 리턴합니다.
- int size() : 저장된 키의 총 수를 리턴합니다.
- Collection<V> values() : 저장된 모든 값을 Collection에 담아서 리턴합니다.
- 객체 삭제
- void clear() : 모든 Map.Entry(키와 값)를 삭제합니다.
- V remove(Object key) : 주어진 키와 일치하는 Map.Entry를 삭제하고 값을 리턴합니다.
키와 값 두 타입을 생성할 때 타입을 넘겨야 합니다.
전체 객체 중에 하나씩 얻고 싶을 경우 두 가지 방법을 사용할 수 있습니다.
- keySet() 메소드로 모든 키를 Set 컬렉션으로 얻은 다음, 반복자를 통해 키를 하나씩 얻는 get() 메소드로 얻습니다.
- entrySet() 메소드로 모든 Map.Entry를 Set 컬렉션으로 얻은 다음, 반복자를 통해 Map.Entry를 하나씩 얻고 getKey(), getValue() 메소드를 이용해 키와 값을 얻습니다.
HashMap
HashMap의 키로 사용할 객체는 hashCode()와 equals() 메소드를 재정의해서 동등 객체가 될 조건을 정해야 합니다.
키와 값의 타입은 기본 타입을 사용할 수 없습니다.
클래스 및 인터페이스 타입만 사용 가능합니다.
선택미션 : 코딩 과정 및 실행 결과 캡처하기
import java.util.*;
public class Example {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("다람쥐", 90);
map.put("도토리", 85);
map.put("나무", 70);
map.put("도토리", 100);
System.out.println("총 Entry 수: " + map.size());
System.out.println("\t도토리 : " + map.get("도토리"));
System.out.println();
Set<String> keySet = map.keySet();
Iterator<String> keyIterator = keySet.iterator();
while (keyIterator.hasNext()) {
String key = keyIterator.next();
Integer value = map.get(key);
System.out.println("\t" + key + " : " + value);
}
System.out.println();
map.remove("도토리");
System.out.println("총 Entry 수 : " + map.size());
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
Iterator<Map.Entry<String, Integer>> entryIterator = entrySet.iterator();
while (entryIterator.hasNext()) {
Map.Entry<String, Integer> entry = entryIterator.next();
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("\t" + key + " : " + value);
}
System.out.println();
map.clear();
System.out.println("총 Entry 수 : " + map.size());
}
}
총 Entry 수: 3
도토리 : 100
나무 : 70
도토리 : 100
다람쥐 : 90
총 Entry 수 : 2
나무 : 70
다람쥐 : 90
총 Entry 수 : 0
Hashtable
Hashtable 은 HashMap 과 동일한 내부 구조를 가지고 있습니다.
Hashtable 도 키로 사용할 객체는 hashCode()와 equals() 메소드를 재정의해서 동등 객체가 될 조건을 정해야 합니다.
HashMap 과의 차이점은 동기화된 (synchronized) 메소드로 구성되어 있기 때문에 멀티 스레드가 동시에 Hashtable 의 메소드를 실행할 수 없습니다. 하나의 스레드가 실행을 완료해야만 다른 스레드를 실행할 수 있습니다.
즉, Thread-safe 합니다.
import java.util.*;
public class Example {
public static void main(String[] args) {
Map<String, String> map = new Hashtable<>();
map.put("spring", "12");
map.put("summer", "123");
map.put("fall", "1234");
map.put("winter", "12345");
Scanner scanner = new Scanner(System.in);
while (true) {
System.out.println("아이디와 비밀번호를 입력해주세요.");
System.out.print("아이디 : ");
String id = scanner.nextLine();
System.out.print("비밀번호 : ");
String password = scanner.nextLine();
System.out.println();
if (map.containsKey(id)) {
if (map.get(id).equals(password)) {
System.out.println("로그인되었습니다.");
break;
} else {
System.out.println("비밀번호가 일치하지 않습니다.");
}
} else {
System.out.println("입력하신 아이디가 존재하지 않습니다.");
}
}
}
}
thread-safe 한 지 테스트해볼까요.
import java.util.*;
public class Example {
public static void main(String[] args) {
Map<String, Integer> map = new Hashtable<>();
Thread threadA = new Thread() {
@Override
public void run() {
for (int i = 1; i <= 1000; i++) {
map.put(String.valueOf(i), i);
}
}
};
Thread threadB = new Thread() {
@Override
public void run() {
for (int i = 1001; i <= 2000; i++) {
map.put(String.valueOf(i), i);
}
}
};
threadA.start();
threadB.start();
try {
threadA.join();
threadB.join();
} catch (Exception e) {}
int size = map.size();
System.out.println("총 객체 수:" + size);
System.out.println();
}
}
총 객체 수:2000
더 알아보기
ArrayList 삭제 최적화 로직
ArrayList 삭제 시, 그 인덱스 뒤에 있는 요소의 인덱스가 하나씩 앞당겨지게 되는데요.
요소가 많고 앞 쪽 인덱스를 삭제하면 성능이 느려질 수 밖에 없습니다.
Java 표준 API 를 만드신 분들께서는 어떻게 고려하고 최적화를 하셨을지 궁금해 지는데요.
ArrayList.remove() 메소드 본문만 봐도 뭔가 심상치 않다는 걸 알 수 있습니다.
/**
* Removes the element at the specified position in this list.
* Shifts any subsequent elements to the left (subtracts one from their
* indices).
*
* @param index the index of the element to be removed
* @return the element that was removed from the list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E remove(int index) {
Objects.checkIndex(index, size);
final Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[index];
fastRemove(es, index);
return oldValue;
}fastRemove() 메소드가 심상치 않습니다. 오브젝트 배열과 인덱스를 매개값으로 넘겨주고 있습니다.
/**
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(Object[] es, int i) {
modCount++;
final int newSize;
if ((newSize = size - 1) > i)
System.arraycopy(es, i + 1, es, i, newSize - i);
es[size = newSize] = null;
}
삭제 전 마지막 인덱스가 삭제한 인덱스보다 크다면 System.arraycopy() 메소드로 복사합니다.
삭제할 인덱스 + 1, i + 1 위치에서 끝까지(newSize - i)의 데이터를 인덱스 i 위치부터 덮어씌웁니다.
삭제 전 마지막 인덱스는 남아 있으므로, null 값을 삽입합니다.
만약 마지막 인덱스를 삭제한다면, null 값 삽입하는 것만 실행합니다.
경계(bound) 체크를 하지 않고 반복문으로 하나씩 일일이 당기지도 않고 삭제한 값을 반환하지 않아서 fastRemove() 메소드라고 명명한 것 같습니다.
삭제한 값은 remove() 메소드에서 대신 반환해주고 있습니다.
modCount 는 무엇일까?
앞서 fastRemove() 메소드를 보았을 때 modCount++; 이라는 로직을 실행하는데요 .
modCount 변수는 무엇일까요?
변수 선언 코드를 가져왔습니다.
/**
* The number of times this list has been <i>structurally modified</i>.
* Structural modifications are those that change the size of the
* list, or otherwise perturb it in such a fashion that iterations in
* progress may yield incorrect results.
*
* <p>This field is used by the iterator and list iterator implementation
* returned by the {@code iterator} and {@code listIterator} methods.
* If the value of this field changes unexpectedly, the iterator (or list
* iterator) will throw a {@code ConcurrentModificationException} in
* response to the {@code next}, {@code remove}, {@code previous},
* {@code set} or {@code add} operations. This provides
* <i>fail-fast</i> behavior, rather than non-deterministic behavior in
* the face of concurrent modification during iteration.
*
* <p><b>Use of this field by subclasses is optional.</b> If a subclass
* wishes to provide fail-fast iterators (and list iterators), then it
* merely has to increment this field in its {@code add(int, E)} and
* {@code remove(int)} methods (and any other methods that it overrides
* that result in structural modifications to the list). A single call to
* {@code add(int, E)} or {@code remove(int)} must add no more than
* one to this field, or the iterators (and list iterators) will throw
* bogus {@code ConcurrentModificationExceptions}. If an implementation
* does not wish to provide fail-fast iterators, this field may be
* ignored.
*/
protected transient int modCount = 0;주석을 보았습니다.
modCount 변수는 리스트가 얼마나 수정됐는지를 기록하는 정수형 변수로 보이네요.
리스트의 크기가 변경되었을 때 증가를 시켜주는데요!
iterator, listIterator 메소드를 구현할 때 이용된다고 합니다.
이 필드 값이 예상치 않게 변경이 되면 반복자에서 ConcurrentModificationException 예외를 발생시켜준다고 하네요.
next() 메소드, remove() 메소드, previous() 메소드, set() 메소드, add() 메소드 연산에서도 예외를 발생시킵니다.
반복자로 값을 순회하고 있는데, 값이 사라지면 의도치 않은 동시성 이슈가 발생할 수 있기에 로직이 추가되었다고 합니다.
그 아래 설명으로는 fail-fast 로직을 제공하는 방법을 설명합니다. add, remove 메소드에서 단순히 modCount 값을 1 증가시켜주면 됩니다. 반복자에서도 예상한 modCount 값과 다르면 ConcurrentModificationExceptions 예외를 던집니다.
만약 fail-fast 를 구현하지 않는다면 필드를 무시하면 됩니다.
여담으로 transient 키워드는 객체를 직렬화할 때 무시하는 필드입니다. 즉, 객체를 저장하는 로직을 세워도 따로 저장하지 않는 다는 걸 명시합니다.
/**
* An optimized version of AbstractList.Itr
*/
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
// prevent creating a synthetic constructor
Itr() {}
...
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
우선 Itr 내부 클래스를 생성할 때 당시의 modCount 가 따로 저장이 됩니다.
next() 메소드를 호출할 때 현재 modCount 와 계속 비교를 하면서 맞지 않다면 ConcurrentModificationException 예외를 발생시킵니다.
그 이후에도 인덱스 경계 체크에서 걸린다면 ConcurrentModificationException 예외를 발생합니다.
Thread-safe 하지 않으므로 checkForComodification() 메소드를 통과 해도
if (i >= elementData.length) 코드 이전에 다른 스레드가 컬렉션을 변경하는 작업을 할 수 있습니다.
그래서 직접 바꾸기 전에도 한 번 체크를 해주는 걸로 보입니다.
List 다른 구현 클래스들
후입선출 (LIFO) 은 나중에 넣은 객체가 먼저 빠져나가고, 선입선출 (FIFO) 은 먼저 넣은 객체가 먼저 빠져나가는 구조입니다.
컬렉션 프레임워크는 LIFO 자료구조를 제공하는 스택 클래스와 FIFO 자료구조를 제공하는 큐 인터페이스를 제공합니다.
Stack
Stack 클래스는 Vector 클래스를 상속합니다. 따라서 thread-safe 한 클래스입니다.
Stack 클래스가 가진 pop() 메소드를 보면 synchronized 동기화된 메소드입니다.
public class Stack<E> extends Vector<E> {
/**
* Creates an empty Stack.
*/
public Stack() {
}
...
/**
* Removes the object at the top of this stack and returns that
* object as the value of this function.
*
* @return The object at the top of this stack (the last item
* of the {@code Vector} object).
* @throws EmptyStackException if this stack is empty.
*/
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
...
}- E push(E item) : 주어진 객체를 스택에 넣는다.
- E pop() : 스택의 맨 위 객체를 빼낸다.
// Example.java
import java.util.*;
public class Example {
public static void main(String[] args) {
Stack<Integer> coinBox = new Stack<>();
coinBox.push(100);
coinBox.push(50);
coinBox.push(500);
coinBox.push(10);
while (!coinBox.isEmpty()) {
Integer integer = coinBox.pop();
System.out.println("꺼내온 동전 : " + integer.intValue() + "원");
}
}
}
꺼내온 동전 : 10원
꺼내온 동전 : 500원
꺼내온 동전 : 50원
꺼내온 동전 : 100원제일 마지막에 넣은 10 부터 500, 50, 100 으로 꺼내집니다.
Queue 다른 구현 클래스들
Queue 인터페이스는 FIFO 자료구조에서 사용되는 메소드를 정의합니다.
다음은 Queue 인터페이스에 있는 메소드입니다.
- boolean offer(E e) : 주어진 객체를 큐에 넣는다.
- E poll() : 큐에서 객체를 빼낸다.
Queue 인터페이스를 구현한 클래스로 앞서 설명한 LinkedList 가 있습니다.
import java.util.*;
public class Example {
public static void main(String[] args) {
Queue<Message> messageQueue = new LinkedList<>();
messageQueue.offer(new Message("sendMail", "나무"));
messageQueue.offer(new Message("sendSMS", "다람쥐"));
messageQueue.offer(new Message("sendKakaotalk", "도토리"));
while (!messageQueue.isEmpty()) {
Message message = messageQueue.poll();
switch (message.command) {
case "sendMail":
System.out.println(message.to + "님에게 메일을 보냅니다.");
break;
case "sendSMS":
System.out.println(message.to + "님에게 SMS를 보냅니다.");
break;
case "sendKakaotalk":
System.out.println(message.to + "님에게 카카오톡을 보냅니다.");
break;
}
}
}
}
나무님에게 메일을 보냅니다.
다람쥐님에게 SMS를 보냅니다.
도토리님에게 카카오톡을 보냅니다.
Deque
Deque 인터페이스는 양 쪽 끝에서 요소 삽입과 삭제를 지원하는 선형 컬렉션입니다.
deque 라는 이름은 "double ended queue" 의 준말이며, '덱' 으로 보통 발음합니다.
대부분 Deque 를 구현하면 요소 갯수에 제한을 두진 않지만, 자바의 Deque 인터페이스는 용량 제한도 추가로 제공합니다.
Deque 인터페이스는 양 쪽 끝에서 요소에 접근하는 메소드를 제공합니다.
요소를 삽입하거나 삭제, 가져오는 메소드를 제공하는 데, 두 가지 형식으로 제공합니다.
연산이 실패하면 예외를 던지거나 특정 값 (null 또는 false) 을 반환합니다.
후자 형식의 삽입 연산은 용량이 제한된 경우를 위해 설계되었습니다.
대부분 삽입 연산을 구현하면 실패하지는 않습니다.
| First Element (Head) |
Last Element (Tail) | |||
| Throws exception | Special value | Throws exception | Special value | |
| Insert | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| Remove | removeFirst() | pollFirst() | removeLast() | pollLast() |
| Examine | getFirst() | peekFirst() | getLast() | peekLast() |
처음(Head)과 끝(Tail)에서 삽입, 삭제, 조회를 하는 메소드를 제공합니다.
연산이 실패하면 예외를 던지느냐, 특정(special) 값을 반환하느냐에 따라서도 분류되어 있습니다.
Deque 인터페이스는 Queue 인터페이스를 상속합니다.
public interface Deque<E> extends Queue<E> {Deque 인터페이스를 FIFO(First-In-First-Out) 처럼 쓸 수 있습니다.
끝(Tail) 에서 요소를 추가하고 처음(Head) 에서 요소를 삭제하면 FIFO 처럼 쓸 수 있습니다.
또한, LIFO(Last-In-First-Out) 처럼도 쓸 수 있습니다. 처음(Head) 에서 요소를 추가하고 삭제하면 됩니다.
List 인터페이스와 달리 요소를 인덱스로 접근하는 걸 지원하지 않습니다.
Deque 인터페이스에 요소를 추가할 때 null 을 추가하는 걸 막지는 않지만, 거의 안 하는 걸 추천드립니다.
null 은 보통 deque 가 비었다고 알려주는 역할을 하기에 null 을 추가하도록 허용하는 구현이면 이 이점을 가져갈 수 없다고 하네요.
ArrayDeque, ConcurrentLinkedDeque, LinkedBlockingQueue, LinkedList 클래스가 대표적인 구현 클래스입니다.
ArrayDeque
크기가 변경되는 배열을 구현한 Deque 인터페이스입니다. 배열 Deque 는 capacity 제한이 없습니다. 사용할 수 있을 만큼 capacity 를 늘립니다. Thread-safe 하지 않아 멀티 스레드 사용 시 동시성 접근을 막는 걸 따로 구현해야 합니다. Null 요소는 금지됩니다.
ArrayDeque 클래스로 Stack 으로 사용할 때, 실제 Stack 객체를 사용하는 것보다 빠릅니다.
그리고 큐로 사용할 때 LinkedList 클래스보다 빠릅니다.
import java.util.*;
public class Example {
public static void main(String[] args) {
ArrayDeque<Integer> arrayDeque = new ArrayDeque<>();
long firstTime = System.nanoTime();
for (int i = 1; i <= 10000; i++) {
arrayDeque.addFirst(i);
}
long lastTime = System.nanoTime();
System.out.println("ArrayDeque 시간 : " + (lastTime - firstTime));
Stack<Integer> stack = new Stack<>();
firstTime = System.nanoTime();
for (int i = 1; i <= 10000; i++) {
stack.add(i);
}
lastTime = System.nanoTime();
System.out.println("stack 시간 : " + (lastTime - firstTime));
arrayDeque = new ArrayDeque<>();
firstTime = System.nanoTime();
for (int i = 1; i <= 10000; i++) {
arrayDeque.addLast(i);
}
lastTime = System.nanoTime();
System.out.println("ArrayDeque 시간 : " + (lastTime - firstTime));
LinkedList<Integer> linkedList = new LinkedList<>();
firstTime = System.nanoTime();
for (int i = 1; i <= 10000; i++) {
linkedList.addLast(i);
}
lastTime = System.nanoTime();
System.out.println("linkedList 시간 : " + (lastTime - firstTime));
}
}
ArrayDeque 시간 : 3292708
stack 시간 : 4545958
ArrayDeque 시간 : 1394542
linkedList 시간 : 1592709반복자(Iterator) 에 fail-fast 기능이 있습니다. 반복자가 생성되어 순회할 동안 Deque 가 수정되면 ConcurrentModificationException 예외를 발생시킵니다. 다만 반복자 자체만으로는 동기화되지 않은 수정을 잡아내지 못하는 경우가 있어서 버그 감지 용도로만 쓰이는 걸 권장합니다.
ConcurrentLinkedDeque
연결된 노드로 동시성을 지원하는 deque 인터페이스를 구현한 클래스입니다.
즉, Thread safe 해서 멀티 스레드에서 접근할 때 안전합니다.
공통 컬렉션으로 다양한 스레드에 공유해야할 때 적절한 선택입니다.
다른 Concurrent 컬렉션 구현 클래스처럼 null 요소 사용을 허용하지 않습니다.
import java.util.*;
import java.util.concurrent.ConcurrentLinkedDeque;
public class Example {
public static void main(String[] args) {
ConcurrentLinkedDeque<Integer> concurrentLinkedDeque = new ConcurrentLinkedDeque<>();
Thread threadA = new Thread() {
@Override
public void run() {
for (int i = 1; i <= 1000; i++) {
concurrentLinkedDeque.add(i);
}
}
};
Thread threadB = new Thread() {
@Override
public void run() {
for (int i = 1001; i <= 2000; i++) {
concurrentLinkedDeque.add(i);
}
}
};
threadA.start();
threadB.start();
try {
threadA.join();
threadB.join();
} catch (Exception e) {}
int size = concurrentLinkedDeque.size();
System.out.println("총 객체 수:" + size);
System.out.println();
}
}
// 총 객체 수:2000
반복자를 생성하고 나서부터, 또는 특정 시점의 deque 상태를 반영하는 요소를 반환하는 약한 일관성(weakly consistent)을 가집니다.
fail-fast 로직을 사용하지 않고 도중에 추가하든, 삭제하든 순회만 합니다.
대부분의 컬렉션과는 달리 size 메소드가 상수 시간이 걸리는 연산이 아닙니다. deque 의 비동기 특성으로 요소의 현재 개수를 결정하는 건 요소를 모두 순회해야 합니다. 순회 도중에 컬렉션이 수정되면 부정확한 결과가 나올 수도 있습니다.
많은 데이터를 연산하는 벌크 연산을 멀티 스레드에서 사용할 때 원자성이 보장받지 않을 수 있습니다.
데이터를 많이 추가하는 addAll 메소드와 순회하는 forEach 메소드를 사용하면 addAll 메소드로 추가한 일부 데이터가 조회될 수도 있습니다.
import java.util.*;
import java.util.concurrent.ConcurrentLinkedDeque;
public class Example {
public static void main(String[] args) {
ConcurrentLinkedDeque<Integer> concurrentLinkedDeque = new ConcurrentLinkedDeque<>();
Thread threadA = new Thread() {
@Override
public void run() {
List<Integer> list = Arrays.asList(6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20);
concurrentLinkedDeque.addAll(list);
}
};
Thread threadB = new Thread() {
@Override
public void run() {
System.out.println("순회 시작");
for (Integer integer : concurrentLinkedDeque) {
System.out.println(integer);
}
System.out.println("순회 완료");
}
};
threadA.start();
threadB.start();
try {
threadA.join();
threadB.join();
} catch (Exception e) {}
int size = concurrentLinkedDeque.size();
System.out.println("총 객체 수:" + size);
System.out.println();
}
}
순회 시작
순회 완료
총 객체 수:15
위 코드를 여러 번 실행하다보면 위처럼 순회가 안되는 경우가 있습니다.
addAll() 메소드가 호출되기 전에 iterator 를 가져오면 순회가 안됩니다.
이 때 ConcurrentModificationException 예외를 발생시키지는 않습니다.
PriorityQueue
우선순위 큐는 우선순위 힙(priority heap) 자료 구조에 기반한 자료구조입니다.
우선순위 큐의 요소는 natural ordering 에 맞춰 정렬됩니다.
또는 생성자에 전달한 Comparator 인터페이스를 사용해 정렬합니다.
우선순위 큐는 null 요소를 허용하지 않습니다.
natural ordering 을 하는 우선순위 큐는 비교 불가능한 객체도 허용하지 않습니다.
만약 비교 불가능한 객체를 저장하면 ClassCastException 예외를 발생합니다.
큐의 head 는 정렬한 다음 가장 작은 요소입니다. 가장 작은 요소가 여러 개라면, 그 중에 하나가 무작위로 head 요소가 됩니다.
우선순위 큐에 제한이 없지만 큐에 저장할 배열의 내부적인 용량은 있습니다. 항상 최소한 큐 사이즈보다는 크다는 걸 보장합니다.
우선순위 큐에 요소를 추가하면 내부 배열 용량은 자동적으로 증가됩니다. 자동 증가 정책은 명시되어있지 않습니다.
우선순위 큐를 (split)iterator() 메소드를 쓸 때 특정 정렬을 하며 순회하지는 않습니다.
정렬한 걸 순회하려면 Arrays.sort(pq.toArray()) 을 사용하는 걸 추천한다고 하네요.
동기화되지 않은 클래스이기에, 멀티 스레드에서 우선순위큐를 동시에 수정하면 안됩니다.
Thread-safe 한 우선순위큐를 사용하려면 PriorityBlockingQueue 클래스를 대신 사용해야 합니다.
큐에 삽입하거나 삭제할 때 O(log(n)) 이 걸리도록 구현했습니다. 객체를 삭제하거나 포함되는지 확인하는 remove(Object), contains(Object) 메소드는 O(n) 입니다. 요소를 가져오는 peek, element, size 메소드는 O(1) 입니다.
내림차순으로 구현하려면 생성자에 Comparator 을 넣어야 합니다. Collections.reverseOrder() 정적 메소드로 넣을 수 있습니다.
import java.util.*;
public class Example {
public static void main(String[] args) {
PriorityQueue<Integer> pq = new PriorityQueue<>();
pq.add(1);
pq.add(15);
pq.add(10);
pq.add(21);
pq.add(25);
pq.add(18);
pq.add(8);
System.out.print(pq); // [1, 15, 8, 21, 25, 18, 10]
}
}추가 과정은 다음과 같습니다.



이진 트리를 계속 추가하다 8을 추가할 때 부모 노드보다 작으므로 스왑합니다.
삭제 과정은 다음과 같습니다.

마지막 노드와 루트 노드를 스왑합니다.
그리고 마지막 노드를 제거합니다.
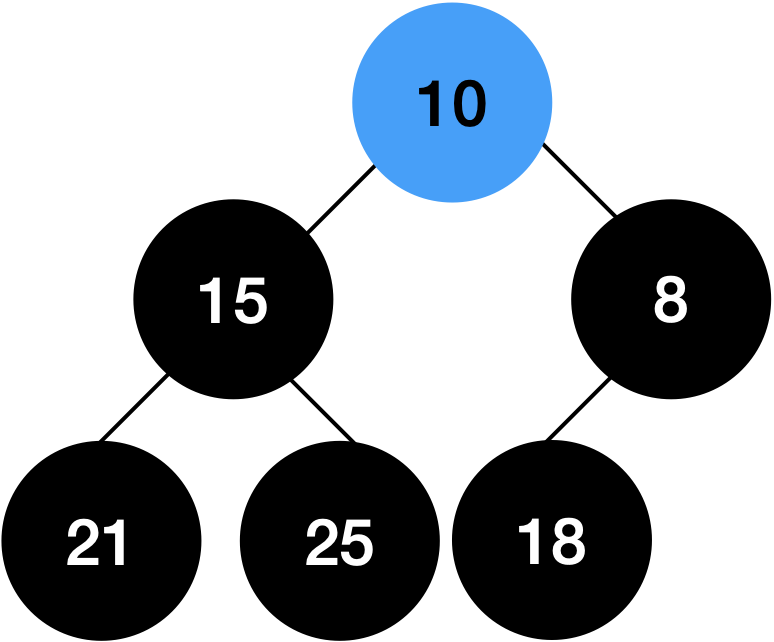
루트 노드의 자식 노드 두 개를 비교합니다.
부모 노드가 무조건 자식 노드보다 작아야 합니다.
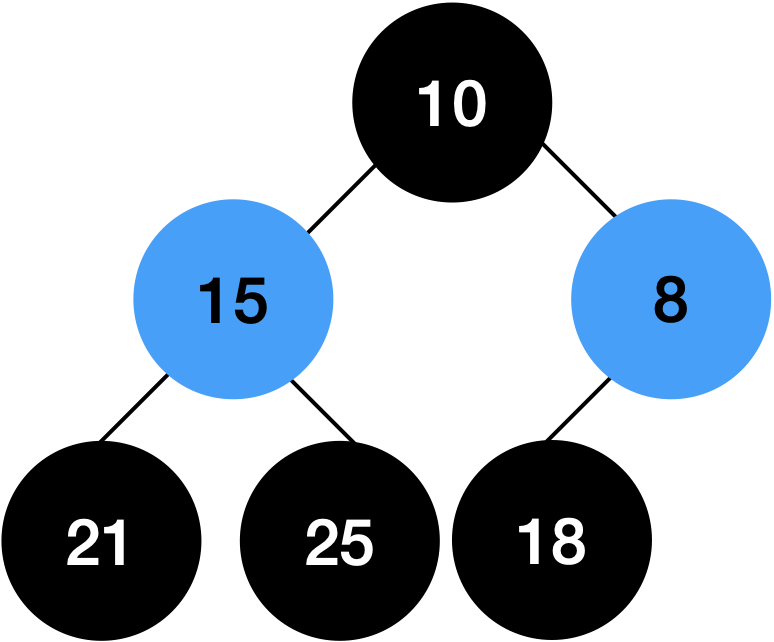
8이 10보다 작으므로 둘을 스왑합니다.

10을 변경하였으므로 10의 자식 노드에 대해서도 검증합니다.
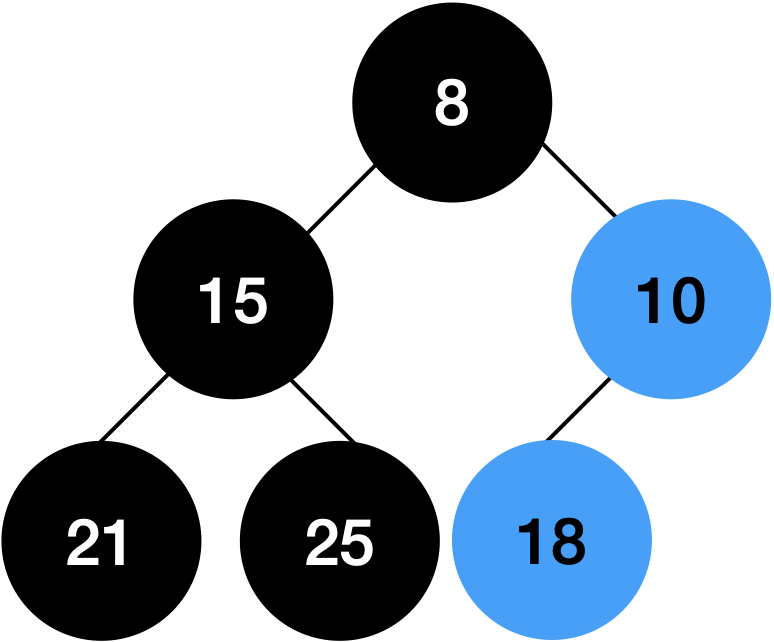
둘의 조건이 맞으므로 더이상 정리하지 않습니다.
처음을 삭제하며 요소가 빌 때 까지 반복하면 오름차순으로 정렬된 값을 확인할 수 있습니다.
import java.util.*;
public class Example {
public static void main(String[] args) {
PriorityQueue<Integer> pq = new PriorityQueue<>();
pq.add(1);
pq.add(15);
pq.add(10);
pq.add(21);
pq.add(25);
pq.add(18);
pq.add(8);
// 1, 8, 10, 15, 18, 21, 25
while (!pq.isEmpty()) {
System.out.println(pq.poll());
}
}
}
스레드 두 개로 추가하면 가끔 맞지 않다는 걸 확인할 수 있습니다.
import java.util.*;
public class Example {
public static void main(String[] args) {
PriorityQueue<Integer> pq = new PriorityQueue<>();
Thread thread1 = new Thread() {
@Override
public void run() {
pq.add(1);
pq.add(2);
pq.add(3);
pq.add(4);
pq.add(5);
}
};
Thread thread2 = new Thread() {
@Override
public void run() {
pq.add(10);
pq.add(11);
pq.add(12);
pq.add(13);
pq.add(14);
}
};
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (Exception e) {}
System.out.println("총 개수: " + pq.size());
System.out.println(pq);
}
}
총 개수: 5
[1, 2, 12, 13, 14]
PriorityQueue 를 PriorityBlockingQueue 으로 바꾼다면 Thread-safe 하여 개수가 10으로 고정됩니다.
import java.util.*;
import java.util.concurrent.PriorityBlockingQueue;
public class Example {
public static void main(String[] args) {
PriorityBlockingQueue<Integer> pq = new PriorityBlockingQueue<>();
Thread thread1 = new Thread() {
@Override
public void run() {
pq.add(1);
pq.add(2);
pq.add(3);
pq.add(4);
pq.add(5);
}
};
Thread thread2 = new Thread() {
@Override
public void run() {
pq.add(10);
pq.add(11);
pq.add(12);
pq.add(13);
pq.add(14);
}
};
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (Exception e) {}
System.out.println("총 개수: " + pq.size());
System.out.println(pq);
}
}
총 개수: 10
[1, 3, 2, 10, 4, 5, 11, 12, 13, 14]
그래도 add() 메소드에 대해서만 synchronized 처리가 되어 있어 호출 순서가 보장되지는 않는데요.
스레드에서 pq 지역변수를 동기화하는 블록으로 만들었습니다.
import java.util.concurrent.PriorityBlockingQueue;
public class Example {
public static void main(String[] args) {
PriorityBlockingQueue<Integer> pq = new PriorityBlockingQueue<>();
Thread thread1 = new Thread() {
@Override
public void run() {
synchronized (pq) {
pq.add(1);
pq.add(2);
pq.add(3);
pq.add(4);
pq.add(5);
pq.add(6);
pq.add(7);
pq.add(8);
pq.add(9);
}
}
};
Thread thread2 = new Thread() {
@Override
public void run() {
synchronized (pq) {
pq.add(10);
pq.add(11);
pq.add(12);
pq.add(13);
pq.add(14);
pq.add(15);
pq.add(16);
pq.add(17);
pq.add(18);
pq.add(19);
}
}
};
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (Exception e) {}
System.out.println("총 개수: " + pq.size());
System.out.println(pq);
}
}
// 총 개수: 19
// [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
Natural Ordering
Natural Ordering 은 Comparable Interface API 설명에 나와있습니다.
Total Ordering 이라는 용어도 있는데요.
Total Ordering 은 모든 값들이 다른 모든 값들과 비교할 수 있어야 합니다.
Natural Ordering 은 사람이 이해하는 데 자연스러운 정렬입니다.
Comparable 인터페이스를 구현한 리스트와 배열은 Collections.sort, Arrays.sort 로 자동으로 정렬이 됩니다.
이 인터페이스를 구현한 객체는 Comparator 명시 없이 Sorted Map, Sorted Set 의 키로 사용할 수 있습니다.
클래스 C가 Natural Ordering 한 걸 consistent with equals 라고도 합니다.
consistent with equlas 는 필요충분조건으로 클래스 C 객체 모든 e1, e2 에 대해 e1.compareTo(e2) == 0 는 e1.equlas(e2) 와 같습니다. ( null 은 예외 )
Natural Ordering 은 필요치 않더라도 consistent with equals 을 강력히 지켜달라고 합니다.
Comparator 명시 없이 Sorted Set, Sorted Map 의 키로 사용할 때 inconsistent with equals 하면 동작이 이상해질 수 있다고 하네요. 이를 equals 메소드 관점에서 general contract 를 위반한다고 하네요.
예를 들어 Sorted Set 에 !a.equals(b) && a.compareTo(b) == 0 인 a, b 키를 add 연산으로 추가할 때 추가가 안됩니다. add 메소드에서 false 를 리턴합니다. Sorted Set 에선 a 와 b 가 동일하다고 판단하기 때문이빈다.
거의 대부분 자바 코어 클래스는 Comparable 을 구현하고 consistent with equals 한 Natural Ordering 을 구현합니다.
예외 클래스가 있는데, java.math.BigDecimal 이 그 예다. 객체가 같이 같으나 정밀도(precision)가 달라도 (4.0, 4.00) 동일하다고 하는 게 natural ordering 이기 때문입니다.
natural ordering 을 가진 클래스 C 를 수학적으로 표현하면 다음과 같습니다.
{ (x, y) such that x.compareTo(y) <= 0 }.
Total Order 의 몫(quotient)은 다음과 같습니다.
{ (x, y) such that x.compareTo(y) == 0 }.
클래스 C의 몫이 동등하고 클래스 C 의 total order 이 natural ordering 하다는 건, compareTo 메소드의 contract 를 따른다고 볼 수 있습니다.
클래스의 natural ordering 이 consistent with equals 할 때, natural ordering 의 몫이 equals() 메소드와 똑같다는 걸 의미합니다.
{ (x, y) such that x.equals(y) }
Set 다른 구현 클래스들
TreeSet
TreeSet은 이진 트리를 기반으로 한 Set 컬렉션입니다.
이진 트리는 여러 개의 노드가 트리 형태로 연결된 구조로, 루트 노드라고 불리는 하나의 노드에서 시작해 각 노드에 최대 2개의 노드를 연결할 수 있는 구조를 가지고 있습니다.
부모 노드의 객체와 비교해서 낮은 것은 왼쪽 자식 노드에, 높은 것은 오른쪽 자식 노드에 저장합니다.
- E first() : 제일 낮은 객체를 리턴
- E last() : 제일 높은 객체를 리턴
- E lower(E e) : 주어진 객체보다 바로 아래 객체를 리턴
- E higher(E e) : 주어진 객체보다 바로 위 객체를 리턴
- E floor(E e) : 주어진 객체와 동등한 객체가 있으면 리턴, 만약 없다면 주어진 객체의 바로 아래의 객체를 리턴
- E ceiling(E e) : 주어진 객체와 동등한 객체가 있으면 리턴, 만약 없다면 주어진 객체의 바로 위의 객체를 리턴
- E pollFirst() : 제일 낮은 객체를 꺼내오고 컬렉션에서 제거함
- E pollLast() : 제일 높은 객체를 꺼내오고 컬렉션에서 제거함
- Iterator<E> descendingIterator() : 내림차순으로 정렬된 Iterator를 리턴
- NavigableSet<E> descendingSet() : 내림차순으로 정렬된 NavigableSet을 리턴
- NavigableSet<E> headSet(E toElement, boolean inclusive) : 주어진 객체보다 낮은 객체들을 NavigableSet으로 리턴, 주어진 객체 포함 여부는 두 번째 매개값에 따라 달라짐
- NavigableSet<E> tailSet(E fromElement, boolean inclusive) : 주어진 객체보다 높은 객체들을 NavigableSet으로 리턴, 주어진 객체 포함 여부는 두 번째 매개값에 따라 달라짐
- NavigableSet<E> subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive) : 시작과 끝으로 주어진 객체 사이의 객체들을 NavigableSet 으로 리턴, 시작과 끝 객체의 포함 여부는 두 번째, 네 번째 매개값에 따라 달라짐
import java.io.IOException;
import java.util.*;
public class Example {
public static void main(String[] args) {
TreeSet<Integer> scores = new TreeSet<>();
scores.add(87);
scores.add(98);
scores.add(75);
scores.add(95);
scores.add(80);
// 75 80 87 95 98
for (Integer s : scores) {
System.out.print(s + " ");
}
System.out.println("\n");
System.out.println("가장 낮은 점수: " + scores.first()); // 가장 낮은 점수: 75
System.out.println("가장 높은 점수: " + scores.last()); // 가장 높은 점수: 98
System.out.println("95점 아래 점수: " + scores.lower(95)); // 95점 아래 점수: 87
System.out.println("95점 위의 점수: " + scores.higher(95)); // 95점 위의 점수: 98
System.out.println("95점이거나 바로 아래 점수: " + scores.floor(95)); // 95점이거나 바로 아래 점수: 95
System.out.println("85점이거나 바로 위의 점수: " + scores.ceiling(85) + "\n"); // 85점이거나 바로 위의 점수: 87
NavigableSet<Integer> descendingScores = scores.descendingSet();
// 98 95 87 80 75
for (Integer s : descendingScores) {
System.out.print(s + " ");
}
System.out.println("\n");
NavigableSet<Integer> rangeSet = scores.tailSet(80, true);
// 80 87 95 98
for (Integer s : rangeSet) {
System.out.print(s + " ");
}
System.out.println("\n");
rangeSet = scores.subSet(80, true, 90, false);
// 80 87
for (Integer s : rangeSet) {
System.out.print(s + " ");
}
System.out.println("\n");
}
}LinkedHashSet
LinkedHashSet 클래스는 HashSet 과는 달리 더블 링크드 리스트를 사용합니다.
링크드 리스트는 삽입 순서가 저장이 되는 특성이 있습니다.
HashSet 에서 저장 순서가 고정되지 않았지만, LinkedHashSet 으로 저장 순서를 유지할 수 있습니다.
void foo(Set s) {
Set copy = new LinkedHashSet(s);
...
}모듈에서 입력으로 Set 을 받고 복사본으로 순서가 같은 결과를 쓰려고 할 때 유용합니다.
사용자도 동일한 순서를 가진다는 걸 인지할 수 있습니다.
LinkedHashSet 은 두 값이 성능에 영향을 끼치는데요. 초기 용량(initial capacity)과 부하 요인(load factor) 값이 있습니다.
HashSet 과 동일하지만 초기 용량을 설정할 때 과도하게 높은 초기 용량을 선택한다고 해서 순회 성능에 초기 용량이 영향을 끼치진 않습니다.
LinkedHashSet 은 Thread-safe 하지 않습니다. 동시적으로 사용하려면 외부적으로 동기화를 해줘야하고 Set s = Collections.synchronizeSet(new LinkedHashSet(...)); 으로 랩핑해서 써야 합니다.
반복자에서 fail-fast 로직이 있지만, 정확하게 비동기화된 케이스를 캐치하지는 못합니다. 버그 탐지에만 쓰는 걸 권장한다고 합니다.
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
...
/**
* Constructs a new, empty linked hash set with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity of the linked hash set
* @param loadFactor the load factor of the linked hash set
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}LinkedHashSet 은 LinkedHashMap 을 사용하는데요, 이를 HashSet 부모 클래스에서 대신 관리해줍니다.
/**
* Constructs a new, empty linked hash set. (This package private
* constructor is only used by LinkedHashSet.) The backing
* HashMap instance is a LinkedHashMap with the specified initial
* capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @param dummy ignored (distinguishes this
* constructor from other int, float constructor.)
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}생성자 구분용으로 boolean dummy 매개변수가 있는 생성자를 호출하면 LinkedHashMap 으로 생성해줍니다.
load factor 은 무엇을 하는 값일까?
load factor 은 현재 크기와 load factor 에 따라서 capacity 를 설정해주는 역할을 합니다.
// LinkedHashSet.java
// Set the capacity according to the size and load factor ensuring that
// the HashMap is at least 25% full but clamping to maximum capacity.
capacity = (int) Math.min(size * Math.min(1 / loadFactor, 4.0f),
HashMap.MAXIMUM_CAPACITY);
// HashMap.java
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
...
return newTab;
}현재 용량에 loadFactor 을 곱한 만큼 Threshold (임계치) 변수에 할당하는 식입니다.
threshold 값에 도달한다면 용량을 두 배 하는 로직으로 동작하고 있습니다.
Map 다른 구현 클래스들
Properties
Properties 는 Hashtable 의 자식 클래스입니다.
Properties 는 키와 값을 String 타입으로 제한한 컬렉션입니다.
주로 확장자가 .properties 인 프로퍼티 파일을 읽을 때 사용합니다.
// build/classes/java/main/database.properties
driver=oracle.jdbc.OracleDriver
url=jdbc:oracle:thin@localhost:1521:orcl
username=scott
password=tiger
admin=\uD64D\uAE38\uB3D9
// Example.java
import java.io.IOException;
import java.util.*;
public class Example {
public static void main(String[] args) throws IOException {
Properties properties = new Properties();
properties.load(Example.class.getResourceAsStream("database.properties"));
String driver = properties.getProperty("driver");
String url = properties.getProperty("url");
String username = properties.getProperty("username");
String password = properties.getProperty("password");
String admin = properties.getProperty("admin");
System.out.println("driver : " + driver);
System.out.println("url : " + url);
System.out.println("username : " + username);
System.out.println("password : " + password);
System.out.println("admin : " + admin);
}
}
driver : oracle.jdbc.OracleDriver
url : jdbc:oracle:thin@localhost:1521:orcl
username : scott
password : tiger
admin : 홍길동
TreeMap
TreeMap은 이진 트리를 기반으로 한 Map 컬렉션입니다.
TreeSet 과 차이점은 키와 값이 저장된 Entry 를 저장합니다.
- Map.Entry<K,V> firstEntry() : 제일 낮은 Map.Entry를 리턴
- Map.Entry<K,V> lastEntry() : 제일 높은 Map.Entry를 리턴
- Map.Entry<K,V> lowerEntry(K key) : 주어진 키보다 바로 아래 Map.Entry를 리턴
- Map.Entry<K,V> higherEntry(K key) : 주어진 키보다 바로 위 Map.Entry를 리턴
- Map.Entry<K,V> floorEntry(K key) : 주어진 키와 동등한 키가 있으면 해당 Map.Entry 리턴, 만약 없다면 주어진 키 바로 아래의 Map.Entry를 리턴
- Map.Entry<K,V> ceilingEntry(K key) : 주어진 키와 동등한 키가 있으면 해당 Map.Entry 리턴, 만약 없다면 주어진 키 바로 위의 Map.Entry를 리턴
- Map.Entry<K,V> pollFirstEntry() : 제일 낮은 Map.Entry를 꺼내오고 컬렉션에서 제거함
- Map.Entry<K,V> pollLastEntry() : 제일 높은 Map.Entry를 꺼내오고 컬렉션에서 제거함
- NavigableSet<K> descendingKeySet() : 내림차순으로 정렬된 키의 NavigableSet을 리턴
- NavigableMap<K,V> descendingMap() : 내림차순으로 정렬된 Map.Entry의 NavigableMap을 리턴
- NavigableMap<K,V> headMap(K toKey, boolean inclusive) : 주어진 키보다 낮은 Map.Entry들을 NavigableMap으로 리턴, 주어진 키의 Map.Entry 포함 여부는 두 번째 매개값에 따라 달라짐
- NavigableMap<E> tailMap(K fromKey, boolean inclusive) : 주어진 키보다 높은 Map.Entry들을 NavigableMap으로 리턴, 주어진 키의 Map.Entry 포함 여부는 두 번째 매개값에 따라 달라짐
- NavigableMap<E> subSet(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive) : 시작과 끝으로 주어진 키 사이의 Map.Entry들을 NavigableMap 컬렉션으로 반환, 시작과 끝 키의 Map.Entry 포함 여부는 두 번째, 네 번째 매개값에 따라 달라짐
import java.util.*;
import java.util.Map.*;
public class Example {
public static void main(String[] args) {
// TreeMap 컬렉션 생성
TreeMap<String, Integer> treeMap = new TreeMap<>();
// 엔트리 저장
treeMap.put("apple", 10);
treeMap.put("forever", 60);
treeMap.put("description", 40);
treeMap.put("ever", 50);
treeMap.put("zoo", 80);
treeMap.put("base", 20);
treeMap.put("guess", 70);
treeMap.put("cherry", 30);
// 정렬된 엔트리를 하나씩 가져오기
Set<Entry<String, Integer>> entrySet = treeMap.entrySet();
for (Entry<String, Integer> entry : entrySet) {
System.out.println(entry.getKey() + "-" + entry.getValue());
}
System.out.println();
// 특정 키에 대한 값 가져오기
Entry<String, Integer> entry = null;
entry = treeMap.firstEntry();
System.out.println("제일 앞 단어: " + entry.getKey() + "-" + entry.getValue());
entry = treeMap.lastEntry();
System.out.println("제일 뒤 단어: " + entry.getKey() + "-" + entry.getValue());
entry = treeMap.lowerEntry("ever");
System.out.println("ever 앞 단어: " + entry.getKey() + "-" + entry.getValue() + "\n");
// 내림차순으로 정렬하기
NavigableMap<String, Integer> descendingMap = treeMap.descendingMap();
Set<Entry<String, Integer>> descendingEntrySet = descendingMap.entrySet();
for (Entry<String, Integer> e : descendingEntrySet) {
System.out.println(e.getKey() + "-" + e.getValue());
}
System.out.println();
// 범위 검색
System.out.println("[c~h 사이의 단어 검색]");
NavigableMap<String, Integer> rangeMap = treeMap.subMap("c", true, "h", false);
for (Entry<String, Integer> e : rangeMap.entrySet()) {
System.out.println(e.getKey() + "-" + e.getValue());
}
}
}
apple-10
base-20
cherry-30
description-40
ever-50
forever-60
guess-70
zoo-80
제일 앞 단어: apple-10
제일 뒤 단어: zoo-80
ever 앞 단어: description-40
zoo-80
guess-70
forever-60
ever-50
description-40
cherry-30
base-20
apple-10
[c~h 사이의 단어 검색]
cherry-30
description-40
ever-50
forever-60
guess-70
Comparable 과 Comparator
TreeSet 과 TreeMap 에 저장되는 키 객체는 저장과 동시에 오름차순으로 정렬됩니다.
그 객체가 Comparable 인터페이스를 구현하고 있어야 합니다.
Comparable 인터페이스에는 compareTo() 메소드가 정의되어 있습니다.
int compareTo(T o) : 주어진 객체와 같으면 0을 리턴, 주어진 객체보다 적으면 음수를 리턴, 주어진 객체보다 크면 양수를 리턴합니다.
// Person.java
public class Person implements Comparable<Person> {
public String name;
public int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Person o) {
if (age < o.age) return -1;
else if (age == o.age) return 0;
else return 1;
}
}
// Example.java
import java.util.*;
public class Example {
public static void main(String[] args) {
TreeSet<Person> treeSet = new TreeSet<>();
treeSet.add(new Person("홍길동", 45));
treeSet.add(new Person("감자바", 25));
treeSet.add(new Person("박지원", 31));
for (Person person : treeSet) {
System.out.println(person.name + ":" + person.age);
}
}
}
감자바:25
박지원:31
홍길동:45
만약 객체가 Comparable 을 구현하고 있지 않다면, 또는 직접 인터페이스를 구현할 수 없다면, 비교자 클래스를 만들어 TreeSet, TreeMap 등에 생성자로 넣을 수 있습니다.
// Fruit.java
public class Fruit {
public String name;
public int price;
public Fruit(String name, int price) {
this.name = name;
this.price = price;
}
}
// FruitComparator.java
import java.util.Comparator;
public class FruitComparator implements Comparator<Fruit> {
@Override
public int compare(Fruit o1, Fruit o2) {
if (o1.price < o2.price) return -1;
else if (o1.price == o2.price) return 0;
else return 1;
}
}
// Example.java
import java.util.*;
public class Example {
public static void main(String[] args) {
TreeSet<Fruit> treeSet = new TreeSet<>(new FruitComparator());
treeSet.add(new Fruit("포도", 3000));
treeSet.add(new Fruit("수박", 10000));
treeSet.add(new Fruit("딸기", 6000));
for (Fruit fruit : treeSet) {
System.out.println(fruit.name + ":" + fruit.price);
}
}
}
IdentityHashMap
IdentityHashMap 은 키를 비교할 때 객체 동등으로 비교합니다. 두 개의 키 k1, k2 가 있으면 k1 == k2 만으로 같다고 판단합니다.
다른 Map, HashMap 의 경우 두 개의 키 k1, k2 은 (k1 == null ? k2 == null : k1.equals(k2) ) 일 떄 같다고 판단합니다.
IdentityHashMap은 일반적인 Map 동작과는 다릅니다. 이는 의도적으로 참조 동등만 필요한 특수한 경우를 지원하기 위해 설계되었습니다.
이 클래스의 전형적인 사용법은 topology-preserving object graph transformations 에 사용됩니다.
예를 들어 serialization, deep-copying 에 사용합니다.
위 같은 transofrmation 을 수행하려면 프로그램이 반드시 이미 처리된 객체 참조를 트랙킹하기 위한 node table 을 유지해야 합니다.
node table 은 실제로 객체가 같더라도 다른 것으로 인식해야 합니다.
또 다른 사용 목적은 프록시 객체를 관리하기 위함입니다. 예를 들어 디버깅 도구에서 디버깅 중인 프로그램에서 각 객체의 프록시 객체를 유지하고 싶을 때 사용합니다.
성능 튜닝할 수 있는 파라미터로 expected maximum size 값입니다. Map 에서 가질 수 있는 key-value mapping 의 최대 갯수입니다.
내부적으로 해시테이블을 처음 구성하는 버킷의 수를 결정하게 됩니다. 버킷의 수와 expected maximum size 의 관계는 정확히 명시되지 않습니다.
만약 실제 크기가 expected maximum size 를 충분히 넘게 된다면 버킷의 수가 증가합니다.
버킷의 수가 증가하며 리해싱(re-hashing) 이 일어나는데 비용이 비쌉니다.
순회할 때에도 버킷의 수에 따라 시간이 비례하므로 순회 성능과 메모리 사용량을 최적화하려면 과도하게 높은 expected maximum size 를 설정하지 않는 것도 중요합니다.
Thread-safe 하지 않습니다. 외부에서 동기적으로 만들거나 Map m = Collections.synchronizedMap(new IdentityHashMap(...)); 으로 동기화 되도록 랩핑합니다.
반복자에서 Fail-fast 로직이 존재합니다. 반복자가 생성된 이후에 Map이 수정된다면 ConcurrentModificationException 예외가 발생합니다.
Hash table 구현은 linear-probe 방식으로 구현되어 있습니다. 키와 값을 배열로 관리합니다. 테이블의 크기가 클 때 분리된 배열을 사용하는 것보다 지역성에 유리합니다. Chaining 으로 구현한 HashMap 보다는 성능이 조금 더 낫습니다.
Linear-probe 는 해시테이블에서 충돌을 해결하기 위한 방식 중 하나입니다.
만약에 키가 충돌하면은 다음 빈 인덱스에 값을 추가합니다.

WeakHashMap
WeakHashMap 은 엔트리가 더이상 사용할 수 없을 때 자동으로 삭제되는 특징이 있습니다.
더 정확하게는 주어진 키에 해당하는 엔트리가 GC 에서 처리되는 게 확실할 때 자동으로 Map 에서 삭제됩니다.
null 값, null 키 모두 지원합니다. HashMap 클래스와 같은 성능을 보입니다.
Thread-safe 하지 않은 클래스입니다. 동기화를 원한다면 Collections.synchronizedMap 을 사용합니다.
이 클래스는 주로 == 연산으로 동등 비교하는 equals() 메소드를 가진 키 객체를 사용하고자 쓰입니다.
그런 키가 처리되면 다시 생성할 수 없습니다. 그래서 WeakHashMap 에서 키를 찾는 게 불가능해집니다.
예를 들어 String 클래스와 같이 객체 동등 로직이 있는 equals 메소드가 아니더라도 완벽하게 동작합니다.
만약 재생성이 가능한 키를 쓴다면 한 번 키가 삭제되고 나서 엔트리가 삭제되면 WeakHashMap 사용할 때 혼동이 있을 수 있습니다.
WeakHashMap 클래스는 가비지 컬렉터(garbase collector)에 의존합니다. GC가 언제든 키를 처리할 수 있기에 알 수 없는 스레드가 조용히 엔트리를 삭제할 수 있습니다. 특히 WeakHashMap 을 동기화하고 수정하는 메소드를 호출하지 않더라도 시간이 지나면서 size 가 달라질 수 있습니다. isEmpty 메소드나 containsKey 메소드, get 메소드, remove 메소드 모두 시간에 따라 동작이 달라질 수 있습니다.
WeakHashMap 에서 값 객체는 보통 강한 참조이긴 하지만, 키에 직접적이든 간접적이든 참조되지 않도록 조심해야 합니다.
값 객체가 간접적으로 WeakHashMap 을 통해 키에 참조할 수가 있습니다. 값 객체가, 연관된 객체가 강하게 값 객체에 연결된 키를 참조하는, 다른 키에 강하게 참조할 수도 있습니다.
이 경우 키가 삭제되지 않는 한 값이 삭제되더라도 자동으로 삭제 처리가 되지 않기 때문인데요.
값들이 반드시 맵에 강한 참조로 저장될 필요는 없다면 삽입할 때 WeakReferences 으로 추가하는 방법도 있다.
m.put(key, new WekReference(value)); 으로 추가하고
가져올 때 언랩핑을 하여 사용합니다.
반복자에서 Fail-fast 동작을 가지고 있으며 반복자가 생성된 이후 Map 이 변경된다면 ConcurrentModificationException 예외가 발생합니다. 비동기적인 동시 수정을 막는 걸 완벽하게 하지 못하므로 버그 잡는 용도로만 사용해야 합니다.
import java.util.*;
public class Example {
public static void main(String[] args) {
WeakHashMap<Integer, String> weakHashMap = new WeakHashMap<>();
Integer key1 = 1000;
Integer key2 = 1001;
weakHashMap.put(key1, "String A");
weakHashMap.put(key2, "String B");
key1 = null;
System.gc(); // Force Garbage Collection
weakHashMap.entrySet().stream().forEach(el -> System.out.println(el));
}
}
// 1001=String BIntegerCache 동작으로 -128 ~ 127 사이의 키를 설정할 시 key1 = null 을 해도 사라지지 않는다는 점 주의하시기 바랍니다.
static 블록으로 -128 ~ 127 캐싱된 Integer 클래스가 메모리에 로딩된 상태이고 프로그램 종료 전까지 사라지지 않습니다.
key1 을 null 으로 저장하고 GC가 처리한다면 자동으로 Map 에서 사라지는 걸 확인할 수 있습니다.
new String() 메소드로 생성하지 않고 String 리터럴을 사용하면 intern() 메소드로 String pool 을 JVM 에서 사용하므로 자동으로 삭제되지 않습니다.
동기화된 컬렉션으로 만들기
컬렉션 프레임워크 대부분은 싱글 스레드 환경에서 사용할 수 있도록 설계되어 있습니다.
여러 스레드가 동시에 컬렉션에 접근한다면 의도하지 않은 동작이 있을 수 있는데요.
Vector와 Hashtable은 동기화된 메소드로 되어 있지만, ArrayList, HashSet, HashMap 은 동기화된 메소드로 구성되어 있지 않습니다. 경우에 따라서 멀티 스레드 환경에서 사용하고 싶을 수도 있는데요.
비동기화된 메소드를 동기화된 메소드로 래핑하는 Collections 의 synchronizedXXX() 메소드를 제공합니다.
- List<T> synchronizedList(List<T> list) : List를 동기화된 List로 리턴
- Map<K,V> synchronizedMap(Map<K,V> m) : Map을 동기화된 Map으로 리턴
- Set<T> synchronizedSet(Set<T> s) : Set을 동기화된 Set으로 리턴
첫 번째 메소드인 synchronizedList() 메소드를 봐볼까요?
/**
* Returns a synchronized (thread-safe) list backed by the specified
* list. In order to guarantee serial access, it is critical that
* <strong>all</strong> access to the backing list is accomplished
* through the returned list.<p>
*
* It is imperative that the user manually synchronize on the returned
* list when traversing it via {@link Iterator}, {@link Spliterator}
* or {@link Stream}:
* <pre>
* List list = Collections.synchronizedList(new ArrayList());
* ...
* synchronized (list) {
* Iterator i = list.iterator(); // Must be in synchronized block
* while (i.hasNext())
* foo(i.next());
* }
* </pre>
* Failure to follow this advice may result in non-deterministic behavior.
*
* <p>The returned list will be serializable if the specified list is
* serializable.
*
* @param <T> the class of the objects in the list
* @param list the list to be "wrapped" in a synchronized list.
* @return a synchronized view of the specified list.
*/
public static <T> List<T> synchronizedList(List<T> list) {
return (list instanceof RandomAccess ?
new SynchronizedRandomAccessList<>(list) :
new SynchronizedList<>(list));
}SynchronizedList<>() 객체를 생성하여 반환해주는데요, 기존과 어떤 차이점이 있을까요?
static class SynchronizedList<E>
extends SynchronizedCollection<E>
implements List<E> {
private static final long serialVersionUID = -7754090372962971524L;
final List<E> list;
SynchronizedList(List<E> list) {
super(list);
this.list = list;
}
SynchronizedList(List<E> list, Object mutex) {
super(list, mutex);
this.list = list;
}
public boolean equals(Object o) {
if (this == o)
return true;
synchronized (mutex) {return list.equals(o);}
}
public int hashCode() {
synchronized (mutex) {return list.hashCode();}
}
public E get(int index) {
synchronized (mutex) {return list.get(index);}
}
public E set(int index, E element) {
synchronized (mutex) {return list.set(index, element);}
}
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
public E remove(int index) {
synchronized (mutex) {return list.remove(index);}
}
public int indexOf(Object o) {
synchronized (mutex) {return list.indexOf(o);}
}
public int lastIndexOf(Object o) {
synchronized (mutex) {return list.lastIndexOf(o);}
}mutex 객체를 잠근 후 기존 List 메소드를 호출합니다.
만약 생성자에 잠글 객체가 없다면 기본으로 자기 자신을 잠급니다.
synchronized (mutex) { ... } 을 랩핑함으로써 동기화된 클래스로 동작하게끔 합니다.
synchronizedList() 메소드의 주석을 보면 반복자(Iterator)를 사용할 때 주의할 점을 알려줍니다.
Iterator, Spliterator, Stream 으로 순회(traverse)할 때 synchronized 블록을 반드시(imperative) 사용해달라고 합니다.
블록을 사용하지 않을 경우 thread-safe 하지 않은 결과를 받을 수 있습니다.
List list = Collections.synchronizedList(new ArrayList());
...
synchronized (list) {
Iterator i = list.iterator(); // Must be in synchronized block
while (i.hasNext())
foo(i.next());
}
synchronizedMap 메소드로 thread-safe 한 Map 으로 만들어서 두 개의 스레드로 테스트할 수 있습니다.
import java.util.*;
public class Example {
public static void main(String[] args) {
Map<Integer, String> map = Collections.synchronizedMap(new HashMap<>());
Thread threadA = new Thread() {
@Override
public void run() {
for (int i = 1; i <= 1000; i++) {
map.put(i, "내용" + i);
}
}
};
Thread threadB = new Thread() {
@Override
public void run() {
for (int i = 1001; i <= 2000; i++) {
map.put(i, "내용" + i);
}
}
};
threadA.start();
threadB.start();
try {
threadA.join();
threadB.join();
} catch (Exception e) {}
int size = map.size();
System.out.println("총 객체 수 : " + size);
}
}
총 객체 수 : 2000수정할 수 없는 컬렉션
수정할 수 없는 (unmodifiable) 컬렉션은 추가, 삭제할 수 없는 컬렉션을 말합니다.
컬렉션 생성 시 저장된 요소를 변경하지 않아야할 때 유용합니다.
첫 번째 방법으로 List, Set, Map 인터페이스의 정적 메소드인 of() 메소드로 생성할 수 있습니다.
List<E> immutableList = List.of(E... elements);
Set<E> immutableSet = Set.of(E... elements);
Map<K,V> immutableMap = Map.of( K k1, V v1, K k2, V v2, ... );
두 번째 방법으로 List, Set, Map 인터페이스의 정적 메소드인 copyOf() 메소드를 이용해 기존 컬렉션을 복사합니다. 복사한 컬렉션은 수정할 수 없는 컬렉션으로 반환합니다.
List<E> immutableList = List.copyOf(Collection<E> coll);
Set<E> immutableSet = Set.copyOf(Collection<E> coll);
Map<K,V> immutableMap = Map.copyOf(Map<K,V> map);
세 번째 방법은 배열로 수정할 수 없는 List 컬렉션을 만들 수 있습니다. Arrays 클래스의 정적 메소드인 asList() 메소드를 이용합니다.
String[] arr = { "A", "B", "C" };
List<String> immutableList = Arrays.asList(arr);
기본 미션 : 직접 정리한 키워드 공유하기
- capacity : 초기 용량으로, 배열을 사용하는 컬렉션의 경우 매개변수로 받는다
- 링크드 리스트 : 체이닝으로 자료를 관리하는 자료구조
- 제너릭 : 클래스 생성 시 타입을 넘겨 다양한 타입을 사용할 수 있습니다.
- Fail Fast : 동기화를 대비해 도중에 컬렉션 데이터 수정 시 예외를 발생시킵니다.
- 우선순위 힙 : 힙은 완전 이진 트리로 우선 순위가 높은 데이터가 먼저 빠져나갑니다. 최소 힙은 부모 노드의 키 값이 자식 노드보다 같거나 작은 완전 이진 트리다. key (부모노드) <= key (자식 노드)
- Natural Ordering : 사람이 읽기에 자연스러운 정렬 방식을 뜻합니다. 숫자의 경우 오름차순, 알파벳의 경우 사전 순이 대표적인 정렬 방식입니다.
- Serialization : 직렬화라고 하며, 자바에서 사용하는 객체나 데이터를 byte 형태로 데이터를 변환하는 기술입니다. JVM 의 메모리에 있는 객체 데이터를 바이트 형태로 기술합니다.
- Deep copy : 깊은 복사로 객체를 복사할 때 참조만 복사하는 게 아닌, 새로운 객체로 같은 데이터로 복사합니다.
- mutex : Mutual exclusion 의 준말로 동시 프로그래밍에서 공유 불가능한 자원의 동시 사용을 피하기 위해 사용하는 알고리즘입니다. 임계 구역으로 불리는 코드 영역에 의해 구현됩니다.
- linear-probe : 해시 테이블의 충돌 관리하는 기법 중의 하나로, 키 충돌 발생 시 순차적으로 연속된 메모리에 값을 저장합니다.
마무리
이번 주에는 컬렉션 프레임워크를 배웠습니다.
자바 API 에서 기본적으로 제공하는 컬렉션 프레임워크들이 굉장히 많았고
다양한 케이스에 적용할 수 있는 컬렉션들이 생각보다 많더라고요.
기본 API 로 채택될만큼 빈도 수가 그래도 있는 컬렉션들이다 보니
적절한 상황에 맞는 컬렉션을 선택하는 것도 좋은 프로그래밍을 하는 데 도움이 될 것 같네요.
컬렉션 프레임워크를 구현하는 다양한 방식도 알게 되어서 공부하는 맛이 있었던 한 주 였네요.
참고 링크
혼공학습단 9기 다른 글 보러가기
2023.01.24 - [자유/방탈출 후기] - [혼공학습단 9기] #7. C언어에 포인터가 있다면 자바엔 스레드다!
[혼공학습단 9기] #7. C언어에 포인터가 있다면 자바엔 스레드다!
안녕하세요, 다람쥐 입니다! 벌써 한빛미디어 혼공학습단이 절반 지나갔네요! 저번 주에 설 연휴에는 쉬고 이제 다시 혼공학습단 9기 혼공자바 완독을 위해 달려가려고 합니다~ 한빛미디어 혼공
itchipmunk.tistory.com
2023.01.17 - [자유/대외 활동] - [혼공학습단 9기] #5. 3주차 자바 기본 API 클래스, 이건 몰랐을걸?
[혼공학습단 9기] #5. 3주차 자바 기본 API 클래스, 이건 몰랐을걸?
안녕하세요, 다람쥐 입니다! 한빛미디어 혼공학습단 9기 혼공자바 3주차 진도 중 두 번째 진도를 나갔습니다. 혼공학습단 9기 혼공자바 3주차 진도 중 두 번째 진도는 바로 자바 기본 API 클래스입
itchipmunk.tistory.com
2023.01.17 - [자유/대외 활동] - [혼공학습단 9기] #4. 3주차 예외, 200% 이해하기
[혼공학습단 9기] #4. 3주차 예외, 200% 이해하기
안녕하세요, 다람쥐 입니다. 벌써 한빛미디어 혼공학습단 9기 혼공자바 3주차 진도를 나가게 됐네요! 혼공 학습단을 하며 혼자 공부하는 자바를 공부하다보니 시간이 참 빠르네요! 연휴가 다가
itchipmunk.tistory.com
2023.01.10 - [자유/대외 활동] - [혼공학습단 9기] #3. 2주차 객체 지향 프로그래밍을 왜 쓸까?
[혼공학습단 9기] #3. 2주차 객체 지향 프로그래밍을 왜 쓸까?
안녕하세요! 여러분들의 궁금증을 해결해 줄 다람쥐입니다. 한빛미디어 혼공학습단 9기 혼공자바 2주차 포스팅입니다. 2주차는 혼공자바 Chapter 6 ~ 9 ( 클래스, 상속, 인터페이스, 중첩 클래스와
itchipmunk.tistory.com
2023.01.08 - [자유/대외 활동] - [혼공학습단 9기] #2. 자바 기본 정말 안다고 생각해?
[혼공학습단 9기] #2. 자바 기본 정말 안다고 생각해?
안녕하세요! 여러분들의 궁금증을 해결해 줄 다람쥐입니다. 한빛미디어 혼공학습단 9기 혼공자바 1주차 포스팅입니다. 1주차는 혼공자바 Chapter 1 ~ 5 ( 자바 설치, 이클립스 설치, 변수와 타입, 연
itchipmunk.tistory.com
2023.01.08 - [자유/대외 활동] - [혼공학습단 #1] 한빛미디어 혼공학습단 9기 선정
[혼공학습단 #1] 한빛미디어 혼공학습단 9기 선정
안녕하세요, 다람쥐입니다. 지난 말에 이메일로 한빛미디어에서 혼공학습단 9기 모집안내를 받았어요! 안그래도 직장을 퇴사하고 자바 공부를 해야하던 터였는데요~ 스스로 목표를 잡고 강제성
itchipmunk.tistory.com