부스패치 #4. PostgreSQL Docker로 로컬 개발 환경 구축하기

안녕하세요.
부스패치 개발자 다람쥐입니다.
로컬 DB 구축 필요성
부스패치는 AWS RDS를 이용하고 있습니다.
데이터베이스 벤더는 PostgreSQL 16.3 버전입니다.
원천 데이터를 저장하는 테이블은 건들 일이 없습니다.
전처리한 테이블을 하루마다 덮어 씌우는 테이블이 많습니다.
따라서 베타 서비스인 개발 단계에서 AWS RDS에 바로 적용하곤 했습니다.
이전 글에서 데이터베이스 칼럼을 모두 바꾸는 큰 작업을 했는데요~
부스패치 #3. TypeORM DB 칼럼 스네이크 케이스 변경 대응
안녕하세요.부스패치 개발자 다람쥐입니다. 스네이크 케이스와 카멜 케이스가 모두 있는 DB 칼럼 여러 테이블의 칼럼명이 스네이크 케이스와 카멜 케이스가 혼용되어 있었습니다.금일 모두 스
itchipmunk.tistory.com
AWS RDS 테이블을 하나하나 바꿨습니다.
그동안 API 서버가 인식하는 테이블과 맞지 않게 됩니다.
운영 서버에 1~2시간의 다운 타임이 발생했습니다.
물론 앞으로 프론트에서 점검 메시지를 띄운다는 등의 조치를 취할 수 있겠지만요.
다운 타임을 최소한 하는 게 아무래도 좋겠죠.
따라서 개발자 모두의 로컬 DB에 먼저 테스트를 마음껏 해 볼 수 있게
환경을 구축할 필요성을 느꼈습니다.
그럼에도 클라우드 환경에서 이런저런 이슈를 만날 수 있겠지만,
최소한의 점검 시간을 잡는 게 목적입니다.
PostgreSQL Docker로 로컬 개발 환경 구축
로컬 환경 구축으로 Docker를 선택했습니다.
직접 PostgreSQL를 설치하지 않았습니다.
어떤 개발 환경이든 일관성을 유지하고 싶었습니다.
Docker로 구축하면 데이터베이스 스키마 이력도 관리할 수 있습니다.
초기 스크립트로 지정하면 새로 데이터베이스를 시작할 때 실행합니다.
데이터베이스가 기존에 있더라도 SQL 이력으로 관리하기에
다른 개발자가 SQL 이력을 그대로 실행해 일관성을 가져갈 수 있게 됩니다.
Docker-compose 코드는 아래와 같습니다.
version: "3.9"
services:
db:
image: postgres:16.3
container_name: boospatch-db
ports:
- 5432:5432
environment:
POSTGRES_USER: xxxx
POSTGRES_PASSWORD: xxxx
POSTGRES_DB: postgres
volumes:
- "./.docker/postgres/:/var/lib/postgresql/data"
- "./init/:/docker-entrypoint-initdb.d/"
도커 이미지 태그는 AWS RDS 환경과 일치하는 16.3 버전을 사용했습니다.
도커 이미지가 잠시 내려가도 데이터를 유지하기 위해 데이터 볼륨을 지정했습니다.
프로젝트 루트 경로의 '.docker/postgres/' 으로 지정했습니다.
만약 데이터를 초기화하고 싶다면 해당 폴더도 직접 삭제해야 합니다.
SQL 스크립트는 'init/' 으로 지정했습니다.
초기 스크립트는 알파벳 순서대로 진행합니다.
순서를 구분하기 위해 파일명 맨 앞에 숫자로 지정했습니다.
'0_boospatch_schema.sql', '1_area_list_data.sql', '2_bjd_code_data.sql', ... 식입니다.
참고로 초기 스크립트는 단 한 번만 시작합니다.
데이터 볼륨에 처음으로 저장할 때만 실행합니다.
모든 초기 스크립트가 성공하든 실패하든 단 한 번만 시작합니다.
따라서 중간에 실패하면 데이터 볼륨을 지우고
도커 이미지를 재시작해야 합니다.
SQL 스크립트 구축
처음 스키마는 AWS RDS에서 가져왔습니다.
DBeaver 에서 스키마를 가져오는 기능은 따로 없더라고요. (제가 못 찾는 걸 수도)
pg_dump를 사용해 직접 가져왔습니다.
(결국 Homebrew로 PostgreSQL을 다운로드하였다는...)
pg_dump -U XXX -d XXX -n XXX -h localhost -p 12345 --schema-only > XXX.sql
--schema-only 옵션으로 스키마만 가져올 수 있습니다.
다른 옵션은 간략하게 설명합니다.
- -U : 유저 이름
- -d : 데이터베이스 이름
- -n : 스키마 이름
- -h : IP 주소
- -p : 포트 번호
- > XXX.sql : 파일로 저장
참고로 AWS RDS에서 퍼블릭 엔드포인트를 무료로 제공하지 않습니다.
(24.02 부터 사용 시 한 달에 약 5$ 씩 과금)
AWS RDS는 로컬에서 터널링하여 사용합니다.
따라서 호스트 주소가 localhost 입니다.
아래와 같이 스키마 덤프가 나타납니다.
도커에서 public 데이터베이스를 만들므로 삭제했습니다.
--
-- PostgreSQL database dump
--
-- Dumped from database version 16.3
-- Dumped by pg_dump version 16.3
...
--
-- Name: XXX; Type: SCHEMA; Schema: -; Owner: pg_database_owner
--
ALTER SCHEMA XXX OWNER TO pg_database_owner;
--
-- Name: SCHEMA XXX; Type: COMMENT; Schema: -; Owner: pg_database_owner
--
COMMENT ON SCHEMA XXX IS 'standard XXX schema';
SET default_tablespace = '';
SET default_table_access_method = heap;
--
-- Name: area_list; Type: TABLE; Schema: XXX; Owner: XXX
--
CREATE TABLE XXX.area_list (
...
);
ALTER TABLE XXX.area_list OWNER TO XXX;
--
-- Name: bjd_code; Type: TABLE; Schema: XXX; Owner: XXX
--
CREATE TABLE XXX.bjd_code (
...
);
ALTER TABLE XXX.bjd_code OWNER TO XXX;
...
--
-- Name: XXX_idx; Type: INDEX; Schema: XXX; Owner: XXX
--
CREATE INDEX XXX_idx ON XXX.danji_list USING btree (...);
...
--
-- PostgreSQL database dump complete
--
초기 데이터(시드)는 DBeaver 클라이언트에서 추출했습니다.
pg_dump로 추출하다 하나씩 추출하는지 너무 느리더라고요.
DBeaver 클라이언트에서 멀티 스레드로 Bulk Insert SQL로 추출하니
속도가 훨씬 빨라서 마음이 편했습니다.
DBeaver 테이블에 마우스 우측 버튼을 누릅니다.
'데이터 내보내기'를 선택합니다.
(영문 버전에선 Export Data... 등이 되겠네요.)
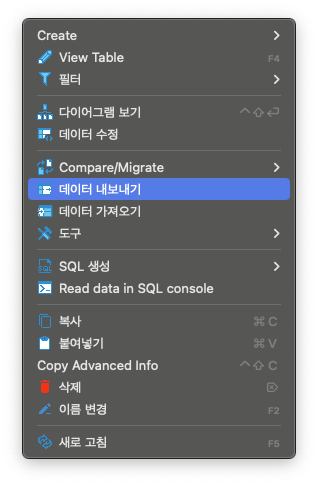
SQL을 선택합니다.
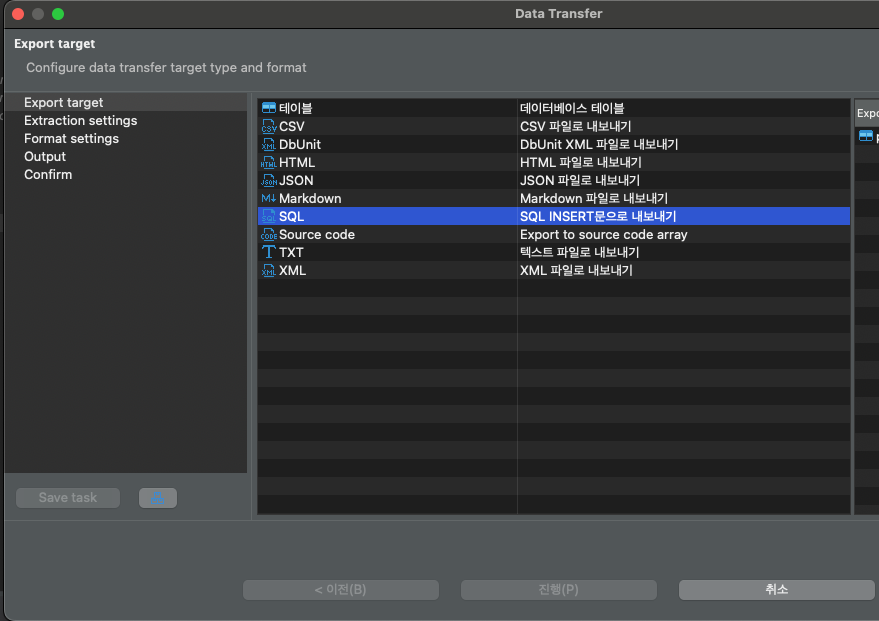
적절한 Fetch size를 설정합니다.
너무 적은 Fetch size면 잦은 Insert 구문으로 분리됩니다.
초기 데이터라 그럴 필요는 없어 Fetch size를 여유롭게 잡았습니다.
운영 서버의 데이터 개수가 만 단위라 10,000개로 설정했습니다.
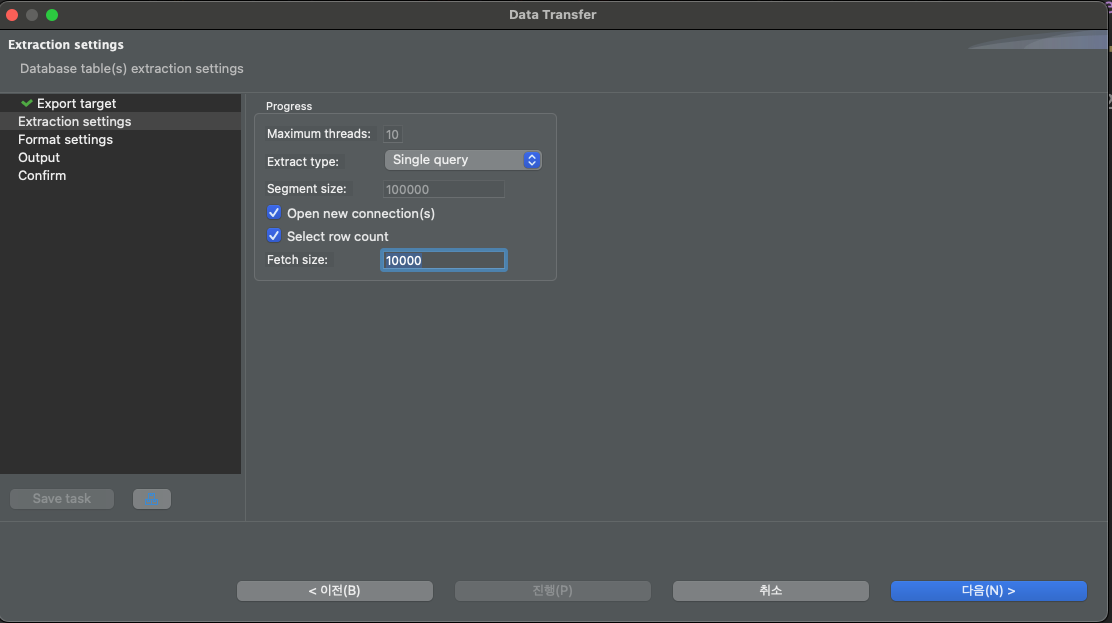
다음으로 세부 설정입니다.
제일 중요한 점은 'INSERT 구문 당 로우 개수'입니다.
Bulk Insert를 해주는 설정으로 역시 10,000개를 설정합니다.
그럼 Insert 구문 하나에 10,000개의 데이터가 들어갑니다.
마지막으로 SQL 파일을 저장할 디렉터리를 설정합니다.
파일명은 기본적으로 테이블 명과 타임스탬프로 이뤄집니다.
고민 없이 디렉터리만 설정합니다.
추출한 Bulk Insert SQL 파일은 그대로
도커 초기 데이터(시드)를 위한 SQL 스크립트로 옮깁니다.
테이블 데이터 간 의존성을 고려해 실행 순서를 설정합니다.
파일 명 맨 앞에 숫자로 버전처럼 관리했습니다.
마무리
Docker로 비교적 간단하게 운영 서버와 비슷한 환경을 빠르게 구축했습니다.
백엔드 애플리케이션, 데이터 전처리 작업이 수월하게 되기를 바라봅니다.
칼럼을 변경할 때 적용 해봤습니다.
변경한 스키마를 바탕으로 로컬 DB에 반영했습니다.
서버 애플리케이션이 정상적으로 동작하는 지 확인한 다음에
운영 서버에 배포했습니다.
로컬에서 운영 서버를 바라봐서 오류가 나는지 확인할 수도 있습니다.
아직은 운영 서버를 바라봐도 큰 문제는 없기에
개발 단계에서도 운영 서버에 올리기 전에 미리 체크하고 있습니다.
만약 운영 서버의 하나 밖에 없는 큐 메시지를 탈취(?)하는 현상이나
실행 시 대량으로 데이터를 변경하는 현상만 없다면
버그 체크 용도로 바라봐도 무방하지 않을까 싶습니다.
(아마 나중에 간다면 운영 단계의 큐 메시지를 처리하는 애플리케이션이 따로 돌겠지만요.)
테스트 코드를 견고히 한다면
CI 단에서 실패하지 않을까도 싶습니다.
로컬 개발 환경이 갖춰져 있으므로
조금 더 즐겁게 개발할 수 있게 됐네요. 😁